

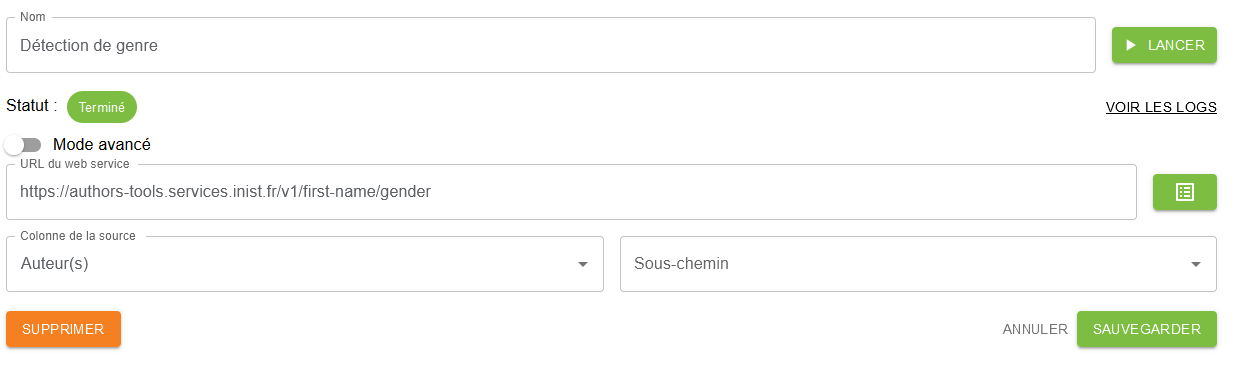
Le Web Service de détection de genre prend en entrée deux formats très spécifiques : “prénom”, “prénom nom” ou “prénom, nom”. Dans cet article, nous allons montrer comment utiliser les recettes de Lodex pour utiliser le WS avec des données diverses issues de CorHal, Istex ou encore le Web Of Science (WOS).
1) Cas n°1 : CorHal
Ces données sont issues de l’API CorHal, pour les charger dans Lodex il faut utiliser le loader “JSON – Compatible API Conditor”.
Les prénoms des auteurs sont présents dans la colonne “authors”.
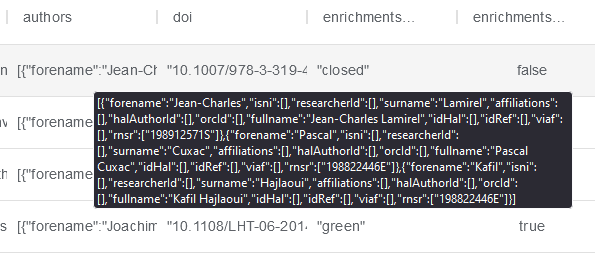
Une fois l’importation faite, il faut suivre les étapes suivantes pour générer une colonne comportant exclusivement les prénoms.
Il faut aller dans les enrichissements, sélectionner mode avancé et écrire une ligne spécifique ci-dessous :
[assign]
path = value
value = get("value.authors").map("forename")

Une fois l’enrichissement fait, une nouvelle colonne comportant les prénoms est créée :
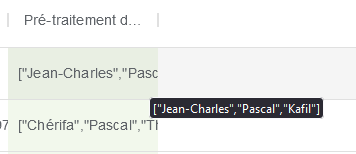
2) Cas n°2 : Istex
Dans ce cas, il faut utiliser le loader spécifique pour Istex (“ZIP – résultat de dl.istex.fr“). Il n’y a pas de pré-traitement spécifique à faire, il suffit juste de lancer le WS sur la colonne “Auteur(s)”.
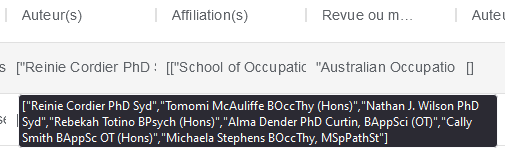
3) Cas n°3: Web Of Science
Pour les données du WOS, il est possible d’utiliser un loader en fonction du format des données. Dans notre cas, nous avons utilisé le loader “TSV – avec tabulations”.
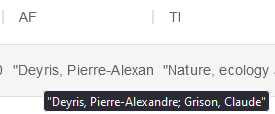
Les noms prénoms des auteurs sont présents dans la colonne “AF”, il faut faire un pré-traitement pour sélectionner uniquement les prénoms.
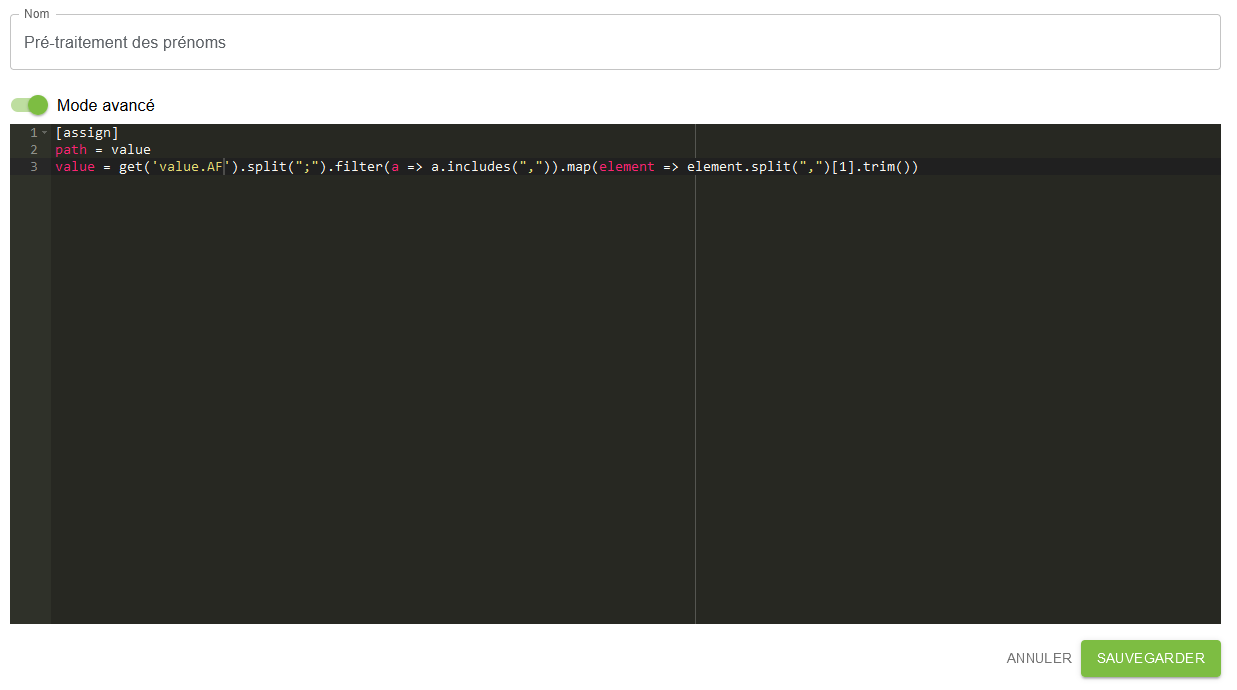
Toujours dans le mode avancé de l’enrichissement, il faut écrire les lignes suivantes :
[assign]
path = value
value = get("value.AF").split(";").filter(a => a.includes(",")).map(element => element.split(",")[1].trim())
Précision sur le code :
- Le
get()permet de récupérer la valeur de la colonne “AF” - Le
split()permet de séparer les auteurs en les divisant à chaque point-virgule, créant ainsi plusieurs éléments dans un tableau [“Nom1, Prénom1”, “Nom2, Prénom2”, “Nom3, Prénom3”, “Nom4”] - La dernière partie du code utilise
split()pour diviser chaque élément en un tableau de sous-chaînes à la virgule, et[1]permet de récupérer uniquement la sous-chaîne correspondant au “Prénom”. - Enfin, le
trim()supprime les espaces en début et en fin de cette sous-chaîne.
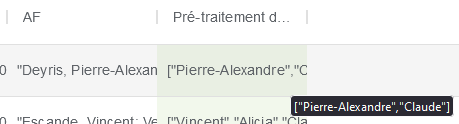
Une nouvelle colonne de prénoms sans les noms de famille est ainsi créée :
A noter que ce dernier traitement est aussi valable pour les données issues de ZOTERO.