
rnsrRuleDetect - Attribution d’identifiant(s) RNSR à une adresse (Alignements)
Le web service attribue, à l’aide de règles, un ou plusieurs identifiants RNSR à partir d’une adresse d’affiliation d’auteur et d’une année de publication.
Quand aucun code RNSR n’est trouvé, le service renvoie un tableau vide.
Règles
Les règles certaines utilisées par affAlign, appliquées à l’adresse de l’affiliation à aligner sont les suivantes:
- le
code_postalou laville_postalede la structure doivent être présents, - et pour au moins une des tutelles (
etabAssoc.*.etab, etetabAssoc.*.etab.natTutEtabvaut «TUTE») :- soit
etabAssoc.*.etab.sigleou leetabAssoc.*.etab.libellesont présents, - soit
etabAssoc.*.etab.libellecommence par «Université» et leetabAssoc.*.etab.libelleest présent (mais pas leetabAssoc.*.etab.sigle).
- soit
- et on trouve la bonne structure :
- soit
etabAssoc.*.labeletetabAssoc.*.numerosont présents proches et en séquence (ex: «GDR2945», «GDR 2945» ou «GDR mot 2945»), - soit
sigleest présent, - soit
intituleest présent.
- soit
- et la structure existait lors de la publication : la date de publication est entre
annee_creationet l’éventuellean_fermeture.
Sachant qu’on appauvrit (casse, accents, tiret, apostrophe) tous les champs.
Ressource
Le RNSR, Référentiel National des Structures de Recherche (français), référence les structures de recherche publiques et privées au niveau national. Il est administré par le ministère de l’enseignement supérieur de la recherche et de l’innovation (MESRI). Il attribue à chaque structure de recherche un identifiant (par exemple 199213009E), et recense différents éléments décrivant la structure comme la date de création, l’éventuelle date de fermeture, l’adresse, le sigle, l’intitulé etc.
Les données actuelles remontent à 2023.
Précautions :
- Quand l’année n’est pas précisée, plusieurs codes RNSR peuvent être associés à un même établissement. Il est donc préférable de renseigner l’année.
- Comme il s’agit d’une recherche de chaîne de caractères, des termes fréquents (comme « DES », « CASE », « PASTEUR », « IMAGES », …) peuvent être repérés comme des sigles de laboratoires.
- Les développés des sigles présentent une écriture complète contrairement à celle du WoS qui les abrège et les traduit (ex: « Institut de Physique » ==> « Inst. of Phys. »).
- La ressource est en français ; les résultats seront meilleurs sur des adresses en français.
- Enrichissement RNSR dans LODEX : https://services.istex.fr/2022/06/20/enrichissement-rnsr-dans-lodex/
- Règles utilisées : https://github.com/Inist-CNRS/ezs/tree/master/packages/conditor#r%C3%A8gles-certaines
- Répertoire du fichier RNSR utilisé : https://github.com/Inist-CNRS/ezs/tree/master/packages/conditor/data
Attribution d'identifiant(s) RNSR à une adresse (Apprentissage)
Attribution de noms d'instituts CNRS à partir d'identifiants RNSR
Utilisation dans Lodex
Sélectionnez le web service dans le catalogue :
Enrichissement : le web service traite chaque document l’un après l’autre. Exemple pour l’extraction de termes à partir du résumé. On parlera de web service synchrone.
* Si vous souhaitez uniquement le code RNSR
Saisir cette URL https://affiliations-tools.services.istex.fr/v1/rnsr/json et sélectionner la colonne dédiée à l’adresse.
Sauvegarder et lancer le traitement
* Si vous souhaitez le code RNSR ainsi que des informations complémentaires
Saisir cette URL https://affiliations-tools.services.istex.fr/v1/rnsr/info et sélectionner la colonne dédiée à l’adresse.
Sauvegarder et lancer le traitement
Informations complémentaires
Une variante de ce service web renvoie aussi des informations associées au code RNSR, telles que l’intitulé, le sigle, les tutelles, des données géographiques, le code labo…
https://affiliations-tools.services.istex.fr/v1/rnsr/info
Données en CSV
Vous pouvez aussi utiliser la variante de ce service qui prend un CSV (séparateur: virgule), et qui en sortie renvoie un CSV (séparateur : point-virgule) qui reprend les données envoyées et leur ajoute une colonne RNSR.
https://affiliations-tools.services.istex.fr/v1/rnsr/csv
Chaque entrée doit contenir l’adresse d’une affiliation (exemple : « University of Bordeaux, IMS, CNRS UMR5218, Talence, F-33405, France »), et éventuellement une année.
| year: 2021 address: CNRS UMR AMAP MONTPELLIER FRA |
==> | 200317641S |
| year: 2021 address: IRD UMR AMAP MONTPELLIER FRA |
==> | 200317641S |
| year: 2021 address: CENBG CNRS/IN2P3 Chemin du Solarium B. P. 120 Gradignan F-33175 France |
==> | |
| year: 2021 address: Nulle part |
==> |


Mode d’enrichissement avancé
Si la plupart des web services sont simples d’utilisation dans LODEX, certains ont besoin de plus d’informations.
C’est le cas de rnsrRuleDetect qui, à partir d’une adresse de laboratoire, renvoie un ou plusieurs identifiants du Référentiel National des Structures de Recherche.
Les laboratoires évoluent au fil du temps : ils changent de nom, fusionnent, se séparent, naissent et meurent. Ainsi ce service demande également une année (typiquement une année de publication, quand on utilise des notices bibliographiques).
Au lieu d’une information unique, deux sont à envoyer : year et address.
Étape 1
La première étape est d’avoir une colonne comportant uniquement les affiliations sous la forme suivante de tableau d’éléments :
[“Denver Nephrology, Denver, Colorado”, “University of Rochester, Rochester, New York”, “Inserm, Université de Picardie, Amiens, France”]
Étape 2
La deuxième étape est consacrée à l’adaptation du script en mode avancé pour obtenir le bon format des données à envoyer au web service.
Le script à modifier pour pouvoir envoyer les 2 informations est visible en sélectionnant l’url du service, en sélectionnant la colonne consacrée aux affiliations, en sauvegardant. puis en activant l’interrupteur Mode avancé :
![]()
Il ressemble à ça :
# load some plugins to activate some statements (URL Connect, exploding, aggregate)
[use]
plugin = basics
plugin = analytics
# Toggle ezs traces (see server stderr log)
[debug]
ezs = false
# We sometime have a stringified value (like "{id:1, name: 'Bob'}"), and we want to parse it, if possible
# This assign command aim is to do that, it update the Affiliations to JSON.parse it if possible.
# Can be simplified with the following statement : value = get('value.Affiliations')
[assign]
path = value
value = update("value.Affiliations", (item) => { try { return JSON.parse(item)} catch {return item } }).get("value.Affiliations")
# Process multivalues of 2 documents
[expand]
path = value
size = 2
# Ensure to process an array
[expand/assign]
path = value
value = get('value',[]).concat(null).filter(Boolean)
# Split the array to process each item
[expand/exploding]
# Group items to build a request for the web service
[expand/expand]
path = value
size = 10
# Uncomment to see each data sent to the webservice
#[expand/expand/debug]
# Send the request to the webservice
[expand/expand/URLConnect]
url = https://affiliations-tools.services.istex.fr/v1/rnsr/json
timeout = 3600000
noerror = false
retries = 5
# rebuild the original array
[expand/aggregate]
Les lignes commençant par # sont des commentaires.
On constate que le champ Colonne de la source est utilisé au début du script, sous l’instruction [assign] (ici, il utilise la colonne nommée Affiliations), et que le champ URL du web service se retrouve à la fin du script, sous l’instruction[expand/expand/URLConnect].
Ce sont les deux lignes qui nous intéressent, car du premier [expand] au dernier [expand/aggregate] se trouve le mécanisme qui s’occupe de créer et d’envoyer les données par lot.
Ce qu’il faut comprendre de la première ligne, c’est que tout document LODEX se trouve dans un objet dont le champ value contient toutes les colonnes, et que c’est aussi ce champ value qui devra, à la fin du traitement, contenir les enrichissements.
Nous transformons alors les lignes du script par défaut :
[assign]
path = value
value = update("value.Affiliations", (item) => { try { return JSON.parse(item)} catch {return item } }).get("value.Affiliations")en
[assign]
path = value.addresses
value = get("value.Affiliations").flatten()La méthode flatten, chaînée à la méthode get, qui renvoie la valeur de la colonne Affiliations, permet d’aplatir le tableau si vous ne l’avez pas fait auparavant lors de la création de la colonne Affiliations:
Un autre changement a été effectué (bravo si vous l’avez repéré) : sur la ligne path, nous avons remplacé value par value.addresses, ce qui ajoute une colonne addresses au document LODEX.
Nous ajoutons une autre instruction [assign], qui va remplacer tout le champ value (donc toute la notice) par la structure que nous devons envoyer au web service :
[assign]
path = value
value = get("value.addresses").map((address) => ({ year: self.value.publicationDate, address }))Pour mieux comprendre la ligne value = qui détermine la valeur du champ value (parce qu’on dit de changer le champ value via le paramètre path = ), on peut essayer de l’indenter :
get("value.addresses")
.map(
(address) => ({
year: self.value.publicationDate,
address
})
)La méthode map va appliquer à tous les éléments du tableau obtenu par get une fonction (anonyme) qui s’écrit :
(address) => ({
year: self.value.publicationDate,
address
})Qui est une syntaxe abrégée pour :
function (address) {
return {
year: self.value.publicationDate,
address: address
}
}C’est map qui fournit son paramètre à cette fonction : address est l’élément du tableau qu’on va remplacer.
Ainsi, le tableau d’adresses à un seul niveau que nous avons vu plus haut donnera ce tableau :
[
{
"year": "2015-07-16",
"address": "Department of Neonatal Medicine, Rouen University Hospital and Région-INSERM (ERI 28), Normandy University, Rouen, France."
},
{
"year": "2015-07-16",
"address": "Department of Biostatistics and INSERM UMR 657, Normandy University, Rouen, France."
}
]et c’est exactement la structure dont a besoin le service que nous interrogeons.
L’interface de LODEX affiche le script et l’aperçu de ce qui va être envoyé au service (en passant la souris au dessus de l’aperçu, les données complètes sont affichées sous forme d’infobulle).
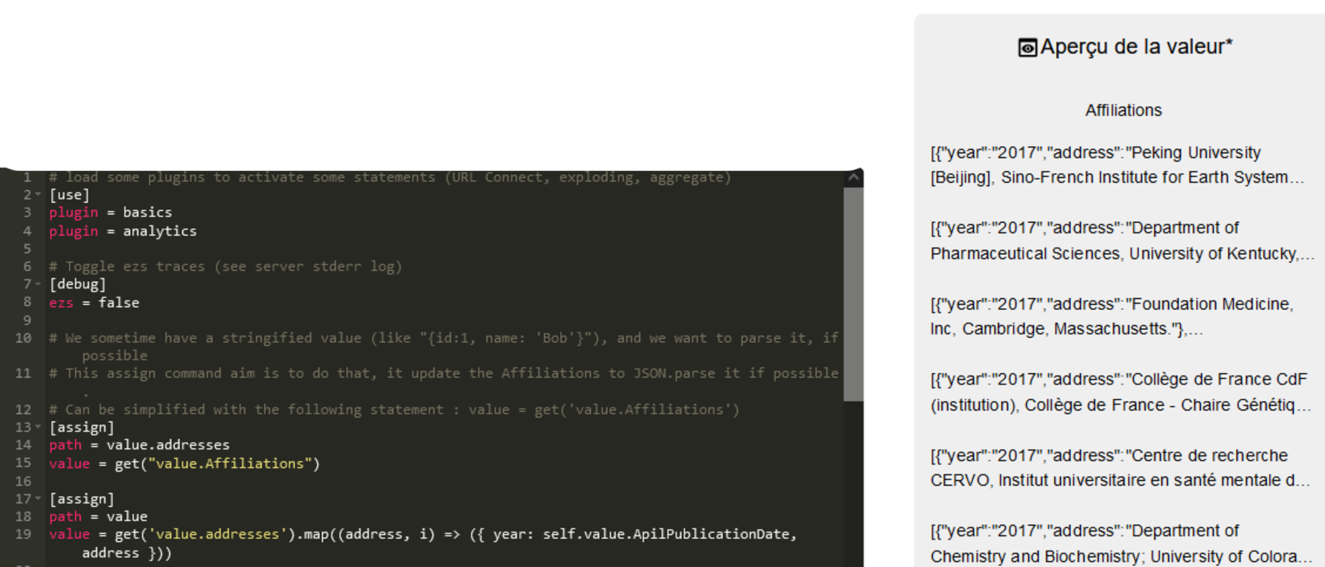
Le script dans son entier est celui-ci (il suffit de le copier-coller pour s’en servir ; évidemment il faut adapter les lignes 15 et 19 de la copie d’écran aux noms de colonnes dont vous disposez) :
# load some plugins to activate some statements (URL Connect, exploding, aggregate) [use] plugin = basics plugin = analytics # Toggle ezs traces (see server stderr log) [debug] ezs = false # We sometime have a stringified value (like "{id:1, name: 'Bob'}"), and we want to parse it, if possible # This assign command aim is to do that, it update the Affiliations to JSON.parse it if possible. # Can be simplified with the following statement : value = get('value.Affiliations') [assign] path = value.addresses value = get("value.Affiliations") [assign] path = value value = get('value.addresses').map((address, i) => ({ year: self.value.ApilPublicationDate, address })) # Process multivalues of 2 documents [expand] path = value size = 2 # Ensure to process an array [expand/assign] path = value value = get('value',[]).concat(null).filter(Boolean) # Split the array to process each item [expand/exploding] # Group items to build a request for the web service [expand/expand] path = value size = 10 # Uncomment to see each data sent to the webservice #[expand/expand/debug] # Send the request to the webservice [expand/expand/URLConnect] url = https://affiliations-tools.services.istex.fr/v1/rnsr/json timeout = 3600000 noerror = false retries = 5 # rebuild the original array [expand/aggregate]
Finitions
On s’aperçoit quand même que la colonne produite est un tableau de tableaux, sans relation avec le tableau des tableaux d’adresses.
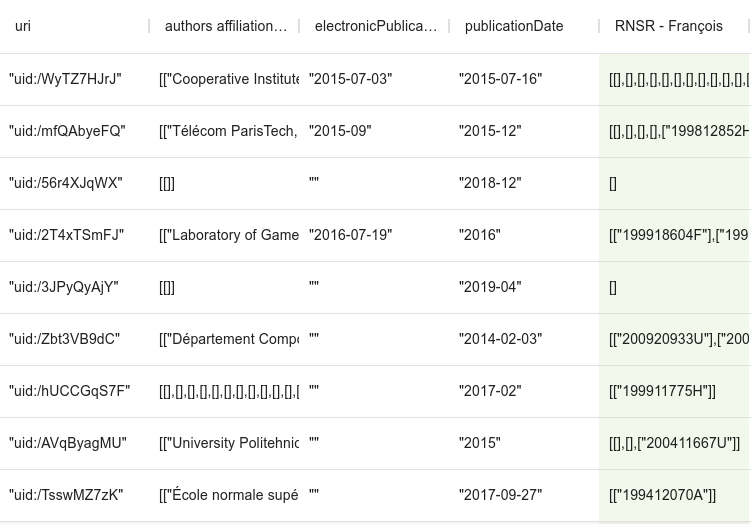
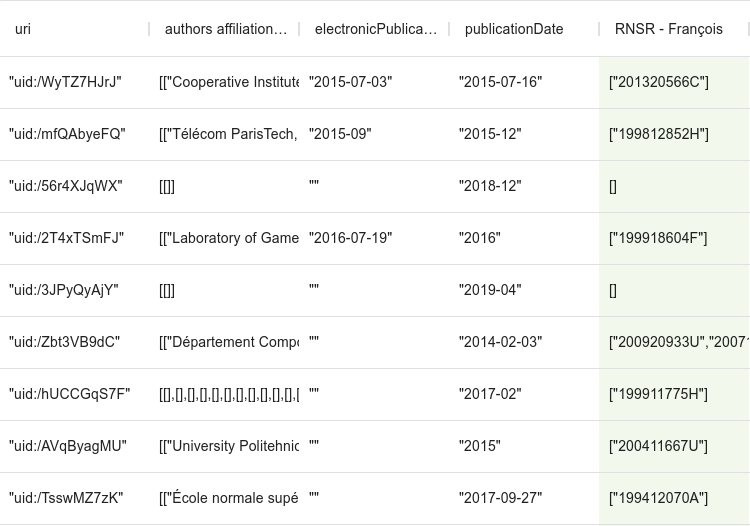
On peut, pour aplanir tout cela, et supprimer les doublons au niveau de la notice, ajouter à la fin du script :
[assign]
path = value
value = get("value",[]).flatten().uniq()qui va réaffecter la valeur de la colonne avec le tableau résultant, mais en le mettant sur un seul niveau (flatten), et en dédoublonnant ses valeurs (uniq).
Pour aller encore plus loin
Pour les plus hardis, voici quelques points purement techniques que vous pouvez approfondir :
- ajouter
.uniq()derrière.flatten(), permet de dédoublonner les valeurs du tableau, ainsi les éléments du tableau ne seront jamais répétés. - ce qui est à droite de
value =dans l’instruction[assign]est du javascript, et plus précisément un chaînage d’instructions lodash. - le javascript à droite de
value =doit tenir sur une ligne. - dans le javascript à droite de
value =, on peut faire appel à des fonctions lodash non chaînées, à condition d’ajouter_.devant le nom de la fonction, et d’ajouter en premier paramètreself, qui est le document courant.
Ainsi, on aurait pu remplacerself.value.publicationDatepar_.get(self, "value.publicationDate"), mais c’était plus long. - l’aperçu de la source n’est pas forcément ce qui est envoyé au service, car le script pouvant avoir n’importe quelle structure, il peut faire complètement autre chose que ce pour quoi il a été initialement prévu (prétraiter des colonnes existantes par exemple). La solution retenue, est de remplacer l’instruction
URLConnectqui fait l’appel au web service par l’instructiontransitqui ne fait rien (elle transmet les données à l’instruction suivante). Donc si une instruction qui modifie les données se trouve en-dessous deURLConnect, elle sera aussi interprétée pour afficher l’aperçu. - le script affiché au passage en mode avancé n’est pas forcément conforme à celui de l’article (en particulier la partie à partir de
[expand]), c’est parce que LODEX déduit ce script de la structure du champ concerné (est-ce une chaîne de caractères, un tableau, …) mais seulement pour le premier document. Il suffit que ce document n’ait pas de valeur pour que LODEX utilise un script moins adapté.
Vous souhaitez connaître les entités de recherche à partir d’une adresse ou d’une affiliation ? Vous souhaitez les homogénéiser ? Vous souhaitez mettre en évidence les coopérations entre ces entités ?
En lançant rnsrRuleDetect sur vos données depuis Lodex, logiciel libre de visualisation, vous obtiendrez les codes RNSR et leur verbalisation ainsi que des représentations graphiques liées.
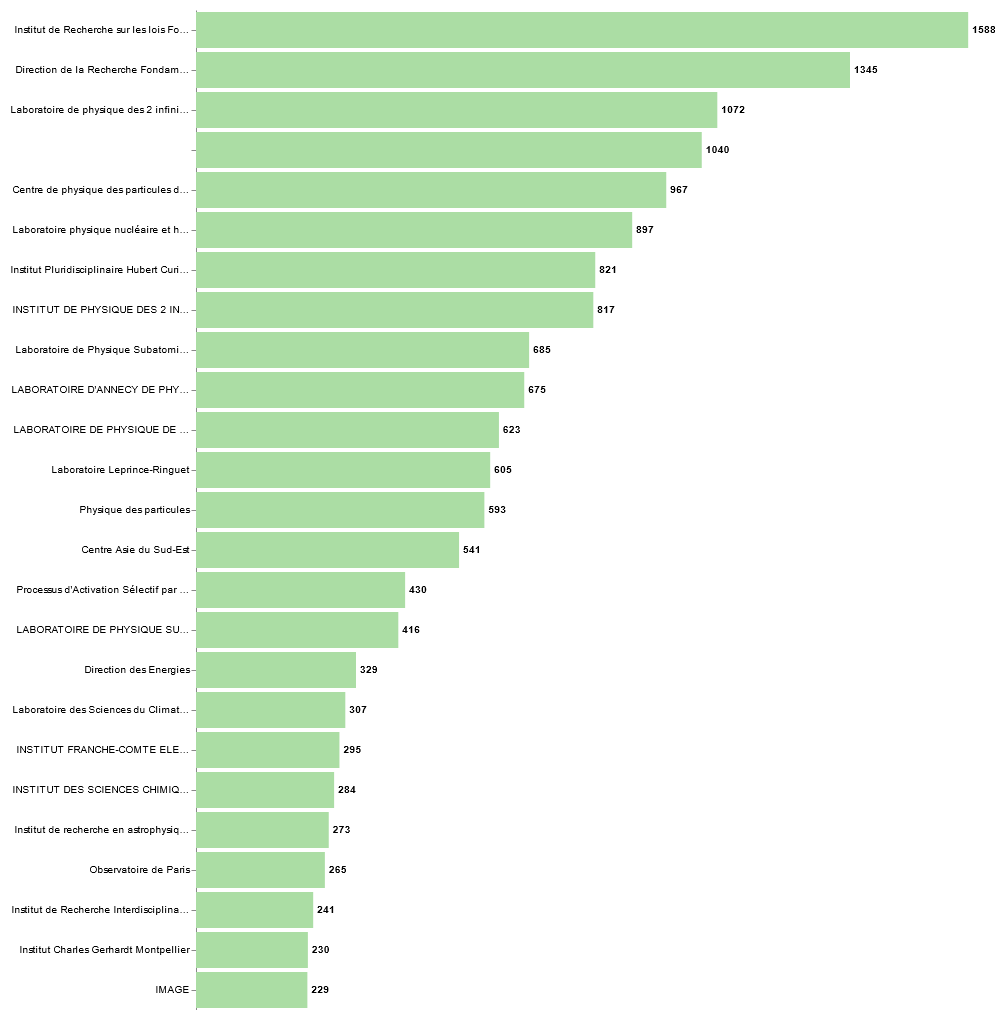
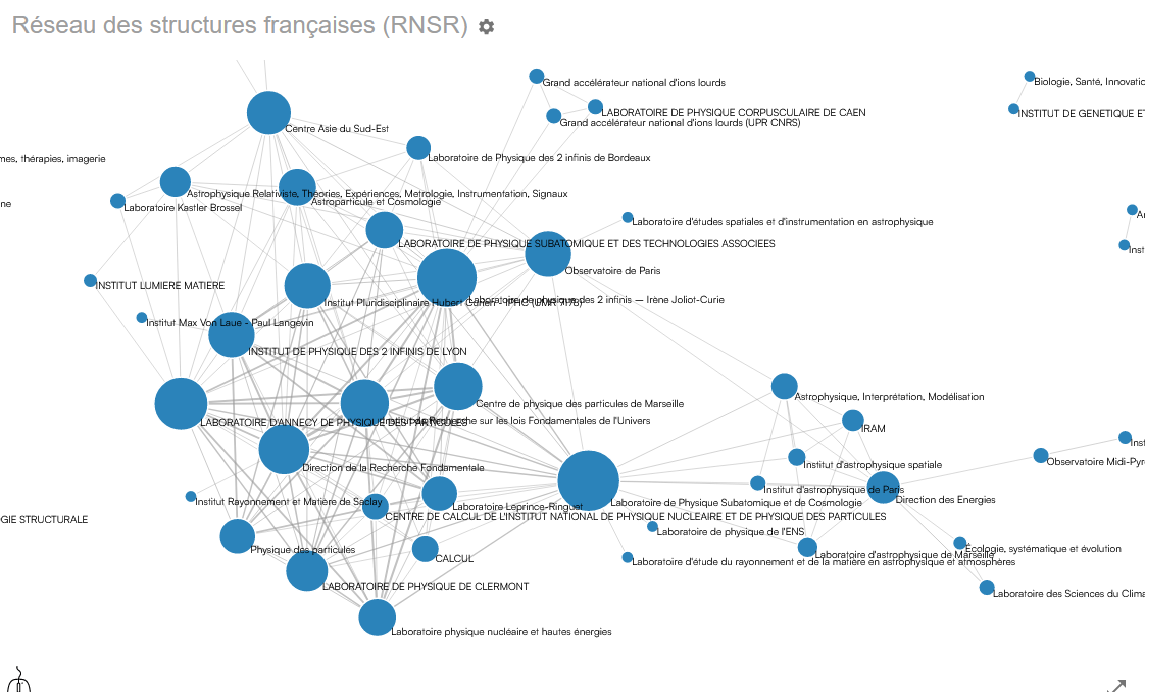
Graphes issus d’une étude réalisée pour la Direction des Données Ouvertes de la Recherche (DDOR) (Comptes rendus annuels d’activité des chercheurs CNRS 2020-2021).