

Mode simple insuffisant
Utiliser un service web dans LODEX pour enrichir les données est, la plupart du temps, très simple:
- on crée un enrichissement,
- on lui donne un nom (qui sera le nom de la colonne créée),
- on donne l’URL du service à utiliser,
- on sélectionne la colonne (le champ) à fournir au service,
- on sauvegarde (bouton
Ajouterla première fois), - on lance.
Mais ça, c’est dans le cas simple où la colonne à utiliser est une valeur structurellement simple (une chaîne de caractères, comme pour un titre, un abstract), et où le service se sert directement d’une valeur simple (littérale).
Il est des services qui ont besoin de plus d’information.
Prenons pour exemple le service qui, à partir d’une adresse de laboratoire, est censé renvoyer un identifiant du Référentiel National des Structures de Recherche.
Il se trouve que les laboratoires évoluent au fil du temps: ils changent de nom, fusionnent, se séparent, naissent et meurent. C’est pour cela que le service RNSR demande aussi une année (typiquement une année de publication, quand on utilise des notices bibliographiques).
Donc, au lieu d’avoir une information unique, on en a deux à envoyer: year et address. Pour faire ça, on utilise une structure appelée « objet » dans le format JSON.
Mode d’enrichissement avancé
D’habitude (dans le cas d’un enrichissement simple), c’est LODEX qui se charge de mettre en forme les données à envoyer au service.
Par exemple, dans le cas du découpage d’une adresse, l’adresse "Inist-CNRS 2, rue Jean Zay CS 10310 F-54519 Vandœuvre-lès-Nancy France" (visible dans l’administration de LODEX) est transformée en un JSON qui pourra être envoyé au service web:
[
{
"id": 1,
"value": "Inist-CNRS 2, rue Jean Zay CS 10310 F-54519 Vandœuvre-lès-Nancy France"
}
]Il fait même encore mieux, puisqu’il rassemble plusieurs adresses à traiter en une seule fois (accélérant les traitements en réduisant le nombre d’allers-retours sur le réseau).
Pour faire cela, il transforme les champs du formulaire d’enrichissement simple en un script (un petit programme) du langage ezs.
Ce script est visible en activant simplement l’interrupteur Mode avancé:
![]()
Il ressemble à ça :
[use]
plugin = basics
plugin = analytics
[assign]
path = value
value = get("value.address")
[expand]
path = value
[expand/exploding]
[expand/expand]
path = value
size = 10
# remove the two lines below to speed up enrichment
[expand/expand/throttle]
bySecond = 5
[expand/expand/URLConnect]
url = https://affiliations-tools.services.inist.fr/v1/addresses/parse
timeout = 5000
noerror = false
retries = 5
[expand/aggregate]
On constate que le champ Colonne de la source est utilisé au début du script, sous l’instruction [assign] (ici, il utilise la colonne nommée address), et que le champ URL du web service se retrouve à la fin du script, sous l’instruction [expand/expand/URLConnect].
Ce sont les deux lignes qui nous intéressent, car du premier [expand] au dernier [expand/aggregate] se trouve le mécanisme qui s’occupe de créer et d’envoyer les données par lot.
Ce qu’il faut comprendre de la première ligne, c’est que tout document LODEX se trouve dans un objet dont le champ value contient toutes les colonnes, et que c’est aussi ce champ value qui devra, à la fin du traitement, contenir les enrichissements.
Cas réel
Jusqu’ici, nous avons supposé qu’un document LODEX contenait une colonne address avec une seule valeur.
En réalité, on trouve souvent des notices bibliographiques avec une adresse par affiliation d’auteur (un des loaders LODEX nomme cette colonne authors affiliations address). Donc au lieu d’avoir une simple chaîne de caractères, nous aurons un tableau (un élément par auteur) de tableaux d’adresses (une adresse par affiliation).
Ce qui ressemble à :
[
[
"Department of Neonatal Medicine, Rouen University Hospital and Région-INSERM (ERI 28), Normandy University, Rouen, France."
],
[
"Department of Biostatistics and INSERM UMR 657, Normandy University, Rouen, France."
]
]Ici, chaque auteur n’a qu’une seule affiliation, d’où des tableaux (délimités par des crochets[]) n’ayant qu’un seul élément chacun, même si ce document a visiblement deux auteurs (le tableau de plus haut niveau a deux éléments).
Pour simplifier, nous allons considérer uniquement les adresses associées à la notice (nous ne nous intéressons plus au lien entre un auteur et son affiliation).
Nous transformons alors les lignes du script par défaut :
[assign]
path = value
value = get("value.authors affiliations address")en
[assign]
path = value.addresses
value = get("value.authors affiliations address").flatten()La méthode flatten, chaînée à la méthode get, qui renvoie la valeur de la colonne authors affiliations address, permet d’aplatir le tableau, et d’obtenir par exemple :
[
"Department of Neonatal Medicine, Rouen University Hospital and Région-INSERM (ERI 28), Normandy University, Rouen, France.",
"Department of Biostatistics and INSERM UMR 657, Normandy University, Rouen, France."
]Un autre changement a été effectué (bravo si vous l’avez répéré) : sur la ligne path, nous avons remplacé value par value.addresses, ce qui ajoute une colonne addresses au document LODEX.
Nous ajoutons une autre instruction [assign], qui va remplacer tout le champ value (donc toute la notice) par la structure que nous devons envoyer au service web) :
[assign]
path = value
value = get("value.addresses").map((address) => ({ year: self.value.publicationDate, address }))Pour mieux comprendre la ligne value = qui détermine la valeur du champ value (parce qu’on dit de changer le champ value via le paramètre path = ), on peut essayer de l’indenter :
get("value.addresses")
.map(
(address) => ({
year: self.value.publicationDate,
address
})
)La méthode map va appliquer à tous les éléments du tableau obtenu par get une fonction (anonyme) qui s’écrit :
(address) => ({
year: self.value.publicationDate,
address
})Qui est une syntaxe abrégée pour :
function (address) {
return {
year: self.value.publicationDate,
address: address
}
}C’est map qui fournit son paramètre à cette fonction: address est l’élément du tableau qu’on va remplacer.
Ainsi, le tableau d’adresses à un seul niveau que nous avons vu plus haut donnera ce tableau :
[
{
"year": "2015-07-16",
"address": "Department of Neonatal Medicine, Rouen University Hospital and Région-INSERM (ERI 28), Normandy University, Rouen, France."
},
{
"year": "2015-07-16",
"address": "Department of Biostatistics and INSERM UMR 657, Normandy University, Rouen, France."
}
]et c’est exactement la structure dont a besoin le service que nous interrogeons.
L’interface de LODEX affiche le script et l’aperçu de ce qui va être envoyé au service (en passant la souris au dessus de l’aperçu, les données complètes sont affichées sous forme d’infobulle).
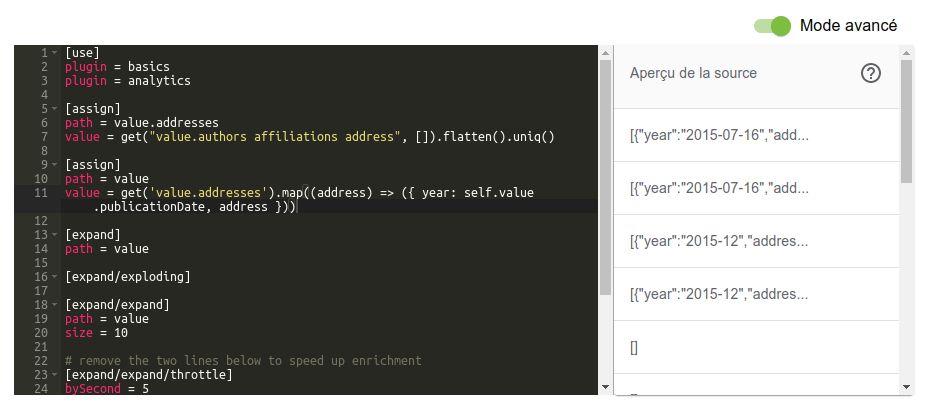 Le script dans son entier est celui-ci (il suffit de le copier-coller pour s’en servir; évidemment il faut adapter les lignes 6, 7 et 11 aux noms de colonnes dont vous disposez) :
Le script dans son entier est celui-ci (il suffit de le copier-coller pour s’en servir; évidemment il faut adapter les lignes 6, 7 et 11 aux noms de colonnes dont vous disposez) :
[use]
plugin = basics
plugin = analytics
[assign]
path = value.addresses
value = get("value.authors affiliations address", []).flatten().uniq()
[assign]
path = value
value = get('value.addresses').map((address, i) => ({ year: self.value.publicationDate, address }))
[expand]
path = value
[expand/exploding]
[expand/expand]
path = value
size = 10
# remove the two lines below to speed up enrichment
[expand/expand/throttle]
bySecond = 5
[expand/expand/URLConnect]
url = https://affiliations-tools.services.inist.fr/v1/rnsr/json
timeout = 5000
noerror = false
retries = 5
[expand/aggregate]Finitions
On s’aperçoit quand même que la colonne produite est un tableau de tableaux, sans relation avec le tableau des tableaux d’adresses.
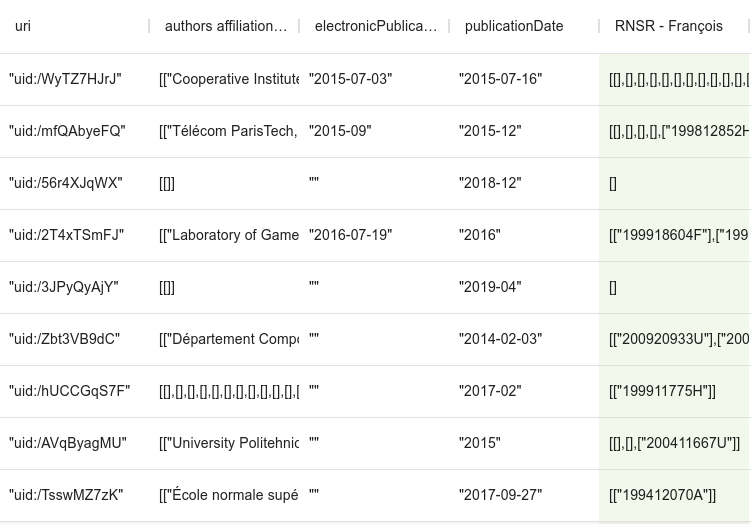 On peut, pour aplanir tout cela, et supprimer les doublons au niveau de la notices, ajouter à la fin du script :
On peut, pour aplanir tout cela, et supprimer les doublons au niveau de la notices, ajouter à la fin du script :
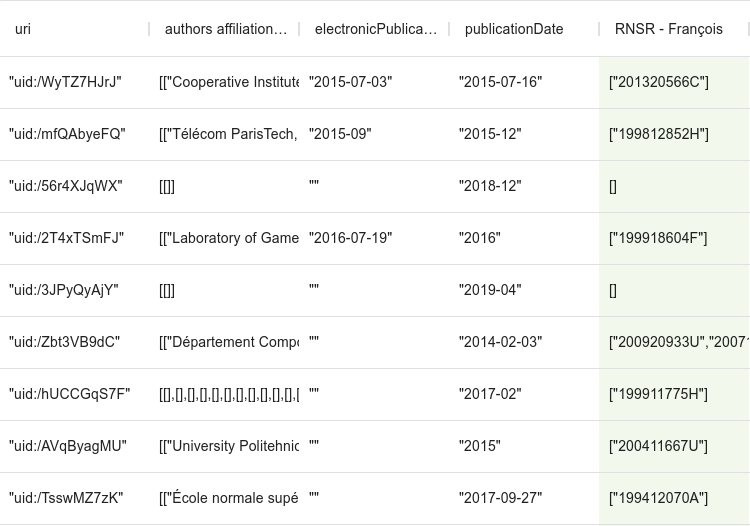
[assign]
path = value
value = get("value",[]).flatten().uniq()qui va réaffecter la valeur de la colonne avec le tableau résultant, mais en le mettant sur un seul niveau (flatten), et en dédoublonnant ses valeurs (uniq).
 Pour aller plus loin
Pour aller plus loin
Pour les plus hardis, voici quelques points purement techniques que vous pouvez approfondir :
- ajouter
.uniq()derrière.flatten(), permet de dédoublonner les valeurs du tableau, ainsi les éléments du tableau ne seront jamais répétés. - ce qui est à droite de
value =dans l’instruction[assign]est du javascript, et plus précisément un chaînage d’instructions lodash. - le javascript à droite de
value =doit tenir sur une ligne. - dans le javascript à droite de
value =, on peut faire appel à des fonctions lodash non chaînées, à condition d’ajouter_.devant le nom de la fonction, et d’ajouter en premier paramètreself, qui est le document courant.
Ainsi, on aurait pu remplacerself.value.publicationDatepar_.get(self, "value.publicationDate"), mais c’était plus long. - l’aperçu de la source n’est pas forcément ce qui est envoyé au service, car le script pouvant avoir n’importe quelle structure, il peut faire complètement autre chose que ce pour quoi il a été initialement prévu (prétraiter des colonnes existantes par exemple). La solution retenue, est de remplacer l’instruction
URLConnectqui fait l’appel au web service par l’instructiontransitqui ne fait rien (elle transmet les données à l’instruction suivante). Donc si une instruction qui modifie les données se trouve en-dessous deURLConnect, elle sera aussi interprétée pour afficher l’aperçu. - le script affiché au passage en mode avancé n’est pas forcément conforme à celui de l’article (en particulier la partie à partir de
[expand]), c’est parce que LODEX déduit ce script de la structure du champ concerné (est-ce une chaîne de caractères, un tableau, …) mais seulement pour le premier document. Il suffit que ce document n’ait pas de valeur pour que LODEX utilise un script moins adapté.