
Teeft - Extraction de termes d’un texte via Teeft
Le service web Teeft extrait, par défaut, les 5 termes les plus spécifiques d’un texte en anglais ou en français.
Il permet ainsi d’avoir une idée de ce dont il est question dans le texte.

Teeft commence par découper le texte en phrases, puis en tokens (des mots, typiquement).
Ensuite, il étiquette grammaticalement ces tokens (nom, adjectif, verbe, …) en prenant compte de la langue.
Il fait de ces tokens des termes, en les sélectionnant selon leur étiquette, et en rassemblant ceux qui se suivent (dans le même groupe nominal).
On enlève les nombres (les termes exclusivement constitués de chiffres), les mots vides (différents selon la langue), les termes trop courts, les termes trop longs (plus de 50 caractères), les termes alphanumériques contenant moins de lettres que de chiffres.
Puis on calcule une spécificité pour chaque terme, en se basant sur sa fréquence par rapport à sa fréquence d’apparition moyenne dans des textes génériques de la langue.
Enfin on filtre les termes pour ne garder que les plus spécifiques.
L’entrée est un texte en anglais ou en français (voir Variantes).
La sortie est une liste de 5 termes par défaut (Voir Variantes).
Le service Teeft originel pour l’anglais est utilisé pour enrichir des millions de documents de la base ISTEX.
Précautions :
- Assurez-vous que la langue du texte corresponde à la variante retenue.
- Idéalement le texte doit contenir plusieurs paragraphes.
Langues
- Anglais :
https://terms-extraction.services.istex.fr/v2/teeft/en - Français :
https://terms-extraction.services.istex.fr/v2/teeft/fr
Nombre de termes
Le paramètre nb est à adapter en fonction des besoins
Pour obtenir 10 termes, il est nécessaire de rajouter ?nb=10 à la fin de l’URL :
https://terms-extraction.services.istex.fr/v2/teeft/fr?nb=10
Nombres compris
Cette variante du web service extrait les termes les plus pertinents d’un texte en anglais ou en français, en conservant les chiffres : il fournit des termes contenant des chiffres (c’est important quand on a des formules chimiques, des grandeurs physiques, …).
La particularité de cette variante est d’encoder les chiffres avant de commencer le traitement et de les décoder ensuite, ce qui évite que les filtres les éliminent.
Ainsi, un multiterme tel que « 5 MW » est représenté en « inffivesup MW » et parvient jusqu’au décodage final.
https://terms-extraction.services.istex.fr/v1/teeft/with-numbers/en
https://terms-extraction.services.istex.fr/v1/teeft/with-numbers/fr
- Cuxac P., Kieffer N., Lamirel J.C. : SKEEFT: indexing method taking into account the structure of the document. 20th Collnet meeting, 5-8 Nov 2019, Dalian, China.
- Paquet
@ezs/teeft, cœur du programme: https://github.com/Inist-CNRS/ezs/tree/master/packages/teeft#readme
Utilisation dans TDM Factory
Ce web service se lance sur :
- un corpus au format CSV
- un corpus Istex au format targz
- un document au format txt avec un encodage UTF8
Sélectionner la bonne variante en fonction de la langue des textes.
Utilisation dans Lodex
Sélectionnez le web service dans le catalogue :
Enrichissement : le web service traite chaque document l’un après l’autre. Exemple pour l’extraction de termes à partir du résumé. On parlera de web service synchrone.
* Si vous avez des textes en anglais
Saisir cette URL https://terms-extraction.services.istex.fr/v2/teeft/en et sélectionner la colonne dédiée au texte.
Sauvegarder et lancer le traitement
* Si vous avez des textes en français
Saisir cette URL https://terms-extraction.services.istex.fr/v2/teeft/fr et sélectionner la colonne dédiée au texte.
Sauvegarder et lancer le traitement
* Si vous souhaitez paramétrer le nombre de termes d’un texte en anglais (ex : 10)
Saisir cette URL https://terms-extraction.services.istex.fr/v2/teeft/en?nb=10 et sélectionner la colonne dédiée au texte.
Sauvegarder et lancer le traitement
* Si vous souhaitez paramétrer le nombre de termes d’un texte en français (ex : 10)
Saisir cette URL https://terms-extraction.services.istex.fr/v2/teeft/fr?nb=10 et sélectionner la colonne dédiée au texte.
Sauvegarder et lancer le traitement
* Si vous souhaitez paramétrer l’extraction de chiffres d’un texte en anglais
Saisir cette URL https://terms-extraction.services.istex.fr/v1/teeft/with-numbers/en et sélectionner la colonne dédiée au texte.
Sauvegarder et lancer le traitement
* Si vous souhaitez paramétrer l’extraction de chiffres d’un texte en français
Saisir cette URL https://terms-extraction.services.istex.fr/v1/teeft/with-numbers/fr et sélectionner la colonne dédiée au texte.
Sauvegarder et lancer le traitement
| Mars Exploration Rover (MER) est une mission double de la NASA lancée en 2003 et composée de deux robots mobiles ayant pour objectif d’étudier la géologie de la planète Mars, en particulier le rôle joué par l’eau dans l’histoire de la planète. Les deux astromobiles ont été lancés au début de l’été 2003 et se sont posés en janvier 2004 sur deux sites martiens susceptibles d’avoir conservé des traces de l’action de l’eau dans leur sol.Chaque rover ou astromobile, piloté par un opérateur depuis la Terre, a alors entamé un périple en utilisant une batterie d’instruments embarqués pour analyser les roches les plus intéressantes :MER-A, rebaptisé Spirit, a atterri le 3 janvier 2004 dans le cratère Gusev, une dépression de 170 kilomètres de diamètre qui a peut-être accueilli un lac ;MER-B, renommé Opportunity, s’est posé le 24 janvier 2004 sur Meridiani Planum.Chaque rover pèse environ 185 kg et se déplace sur six roues mues par l’énergie électrique fournie par des panneaux solaires … | ==> | “term”: “deux robots”, “frequency”: 2, “specificity”: 1″term”: “panneaux solaires”, “frequency”: 2, “specificity”: 1″term”: “mars exploration rover mer”, “frequency”: 1, “specificity”: 0.5″term”: “mission double”, “frequency”: 1, “specificity”: 0.5″term”: “deux robots mobiles”, “frequency”: 1, “specificity”: 0.5 |


Dans LODEX, les enrichissements sont par défaut en mode simple, et n’ont que peu de paramètres.
Déchiffrons ensemble le script qui se cache derrière le web service Teeft.
Pour créer un enrichissement, il faut avoir chargé un corpus (via l’administration de LODEX).
Ce corpus dispose d’une colonne Résumé contenant un résumé en anglais.
Ensuite, il faut se rendre dans le menu Données / Enrichissements :
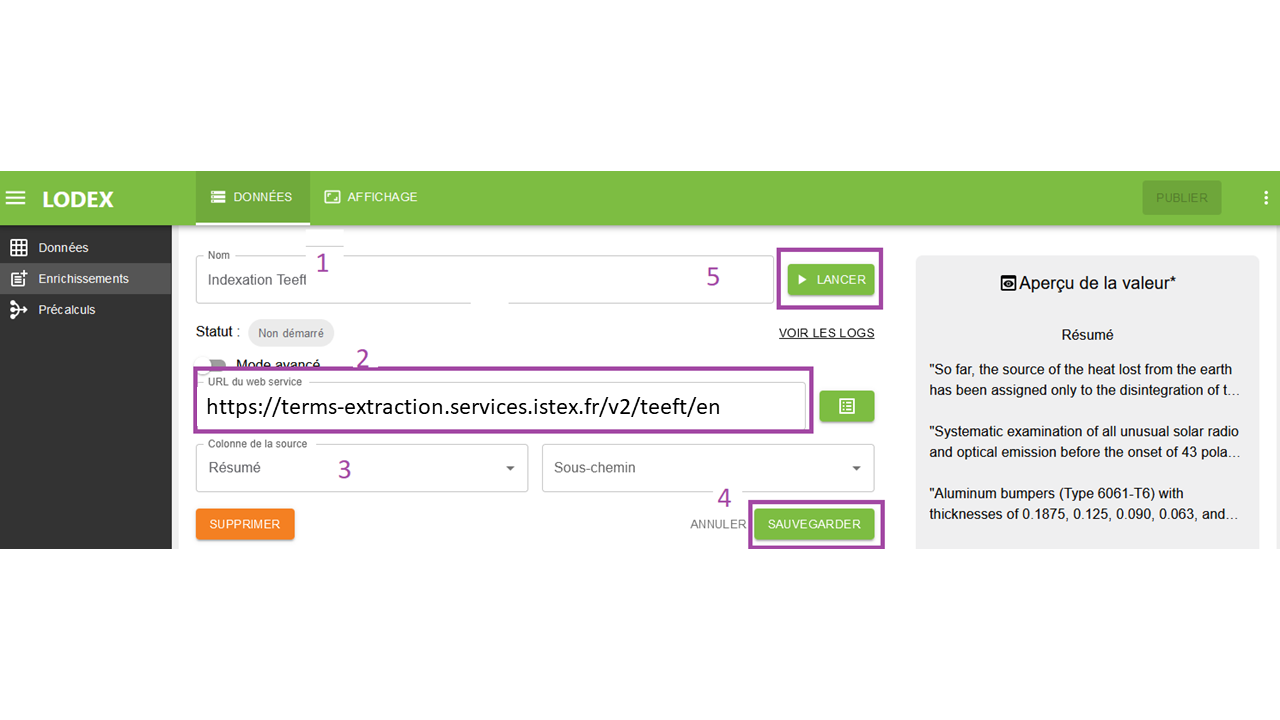
1. Nommons l’enrichissement que nous créons Indexation Teeft, ce sera le nom de la colonne correspondante.
2. Le service web à utiliser est décrit sur la page Extraction de termes d’un texte via Teeft d’ISTEX TDM et est à sélectionner.
Attention de choisir le web service correspondant à la langue de vos résumés.
L’URL du service web est https://terms-extraction.services.inist.fr/v2/teeft/en si l’on veut les 5 premiers termes d’indexation de textes en anglais.
3. Ensuite, sélectionnons la colonne Résumé puisqu’il s’agit de celle dont nous voulons extraire les termes pertinents.
4. Il reste à cliquer sur Sauvegarder pour créer l’enrichissement, et permettre d’accéder au script correspondant à ces paramètres.
5. Une fois l’enrichissement sauvegardé, deux nouveaux boutons apparaissent : Lancer et Supprimer.
Visualiser le script et expliquer les actions
En actionnant le bouton Mode avancé, le formulaire est remplacé par un éditeur présentant le script généré à partir de ses paramètres.
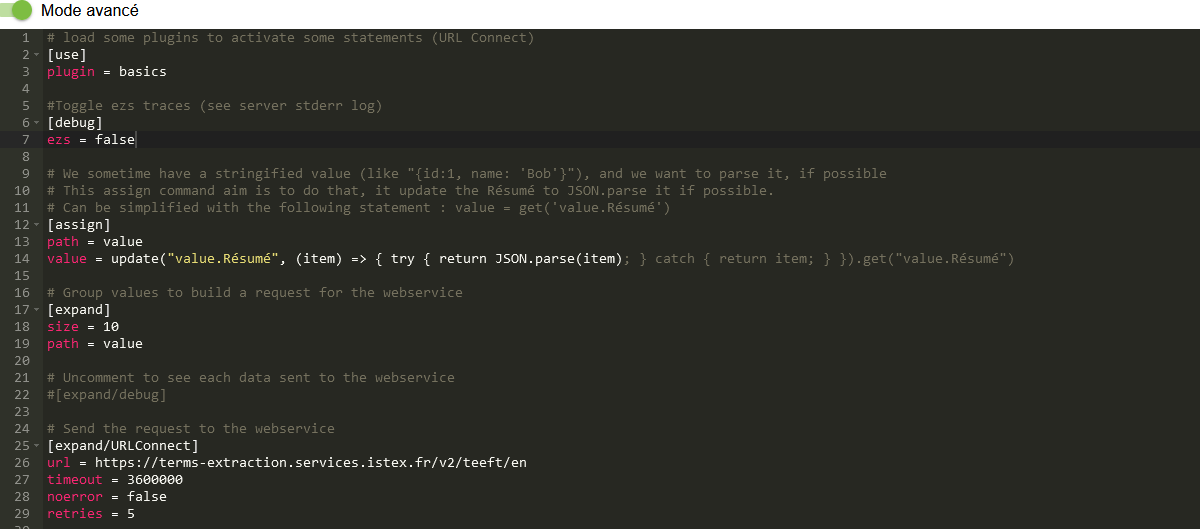
Le script affiché est écrit dans un langage de traitement de flux de données appelé ezs.
Ici, les crochets marquent la présence d’une instruction ezs.
Détaillons chacune d’entre elles.
use
# load some plugins to activate some statements (URL Connect)
[use]
plugin = basicsL’instruction use déclare les plugins (ou modules) du langage ezs que le script va utiliser.
debug
[debug]
ezs=falseL’instruction debug permet au script de laisser des traces dans le fichier log de lodex, quand son paramètre ezs est true.
Pour pouvoir lire ces traces, il faut avoir accès à ce fichier.
C’est possible si vous avez accès à ezMaster, par exemple.
assign
L’instruction assign ajoute un champ, ou bien modifie simplement un champ déjà existant de l’objet du flux qu’elle est en train de traiter.
# We sometimes have a stringfield value (like "{id:1, name: 'Bob'}"), and we want to parse it, if possible
# This assign command's aim is to do that, it updates the abstract to JSON.parse it if possible.
# Can be simplified with the following statement : value = get('value.abstract')
[assign]
path = value
value = update("value.Résumé", (item) => { try { return JSON.parse(item); } catch { return item; } }).get("value.Résumé")Ici, le commentaire explique pourquoi la ligne avec le paramètre value est si longue, et que dans les cas les plus courants, on peut se contenter d’écrire cette instruction comme suit :
[assign]
path = value
value = get("value.Résumé")Cette instruction va modifier le champ value (donc l’objet contenant toutes les colonnes) pour lui affecter uniquement sa colonne Résumé.
On passera donc d’un objet du genre :
{
"id": "001",
"value": {
"Revue": "Le nom de la revue est ici",
"Résumé": "Le résumé se trouve ici",
...
}
}à un objet ressemblant à :
{
"id": "001",
"value": "Le résumé se trouve ici"
}ce qui, si vous y avez prêté attention, est le format d’entrée nécessaire au service web Teeft.
Là aussi, LODEX a tout préparé pour nous, et en principe nous n’aurons rien à toucher.
expand
# Group values to build a request for the webservice
[expand]
size = 10
path=value
# Uncomment to see each data sent to the webservice
#[expand/debug]
# Send the request to the webservice
[expand/URLConnect]
url = https://terms-extraction.services.istex.fr/v1/teeft/fr?nb=10
timeout = 3600000
noerror = false
retries = 5
L’instruction expand est spéciale : elle fabrique un tableau de 10 éléments (size=10), tous les dix objets qu’elle reçoit, et exécute une sorte de sous-script.
Ici, le sous-script contient l’instruction URLConnect.
Considérons que URLConnect (dont nous verrons les paramètres plus bas) sert à appeler le service web, nous voyons que cette partie du script sert à envoyer plusieurs Résumés d’un coup au web service, réduisant ainsi le nombre de fois auquel on y fait appel.
Sachant que la rapidité du script dépend beaucoup du nombre d’appels au service web, il peut être salutaire de réduire ce nombre d’appels.
Cela peut se faire simplement en augmentant le paramètre size de expand :
[expand]
size = 100
path = valueEn le mettant à 100, nous faisons des paquets de 100 Résumés à envoyer au service web (divisant par 10 le nombre de requêtes).
Cependant, restons conscients que suivant la lourdeur du traitement à effectuer, augmenter size ne permettra pas forcément au service web d’être plus rapide.
En particulier, passer sa valeur à plus que 100 n’aura que rarement un effet positif.
Mais c’est un des paramètres qu’on peut se permettre de faire varier si l’enrichissement est trop long.
URLConnect
[expand/URLConnect]
url = https://terms-extraction.services.inist.fr/v1/teeft/fr?nb=10
timeout = 5000
noerror = false
retries = 5Le premier paramètre de URLConnect est évidemment l’url à utiliser.
Il y a ici un argument qu’on peut faire varier : nb. Il n’affecte pas les performances du service, mais seulement le nombre de termes à renvoyer.
retries représente le nombre d’essais que LODEX fait si l’appel au service échoue avant d’abandonner.
Mieux vaut ne pas l’augmenter, car il ne sert déjà que dans des cas extrêmes.
D’ailleurs, il peut expliquer des temps d’interrogation longs (au cas où l’URL ne serait pas bonne, par exemple).
De même, modifier noerror serait contre-productif : la seule autre valeur possible est true, et elle signifie qu’aucune erreur n’est signalée.
timeout en revanche, peut s’avérer utile.
Il arrive que certains services web nécessitant des calculs relativement lourds mettent plus que 5 secondes à répondre.
C’est un des cas où aucune erreur n’arrive à LODEX, car il ignore toute réponse arrivant après le délai imparti.
C’est timeout qui fixe ce délai, dans ce script à 5000 millisecondes.
L’onglet Données affichant les colonnes enrichies affiche undefined lorsque le timeout est dépassé.
C’est alors un fort indice qu’il faut augmenter la valeur de timeout.
Il peut arriver qu’un service prenne plus d’une minute pour un calcul (dépendant de la complexité du calcul, de la charge du serveur, …), n’hésitez donc pas à doubler la valeur de timeout quand vous obtenez des valeurs undefined dans la colonne enrichie correspondant au nom de l’enrichissement.
On peut ensuite aller voir le résultat en cliquant sur Données.
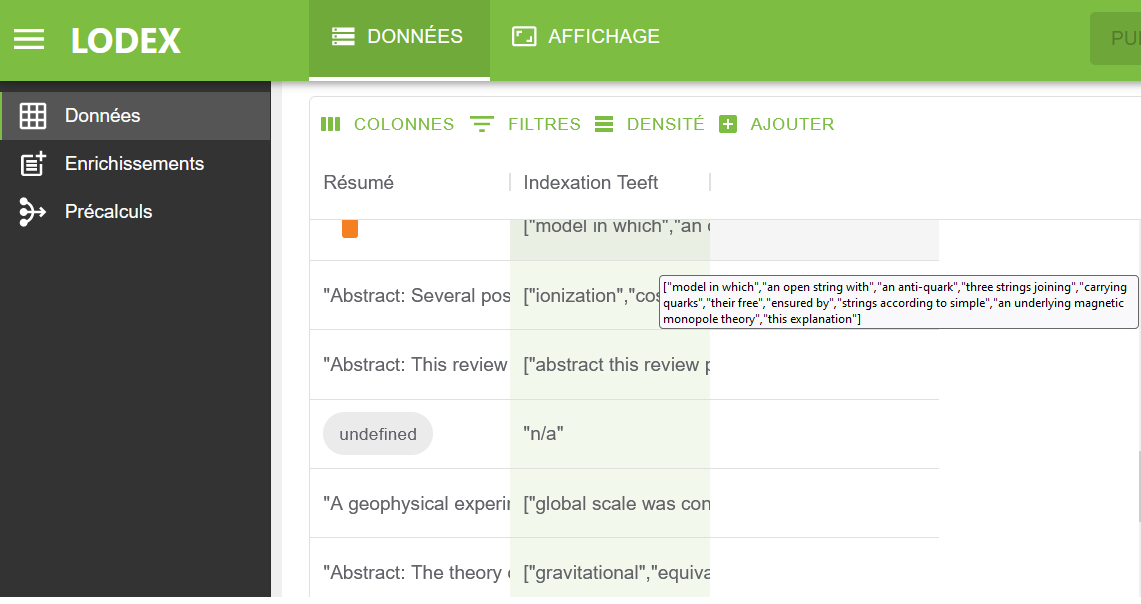
Voilà vous savez tout. À vous de jouer.
Vous avez un corpus et vous souhaitez en connaître le contenu ? En lançant Teeft sur vos données depuis Lodex, logiciel libre de visualisation, vous obtiendrez une indexation pour chaque document et des représentations graphiques liées.
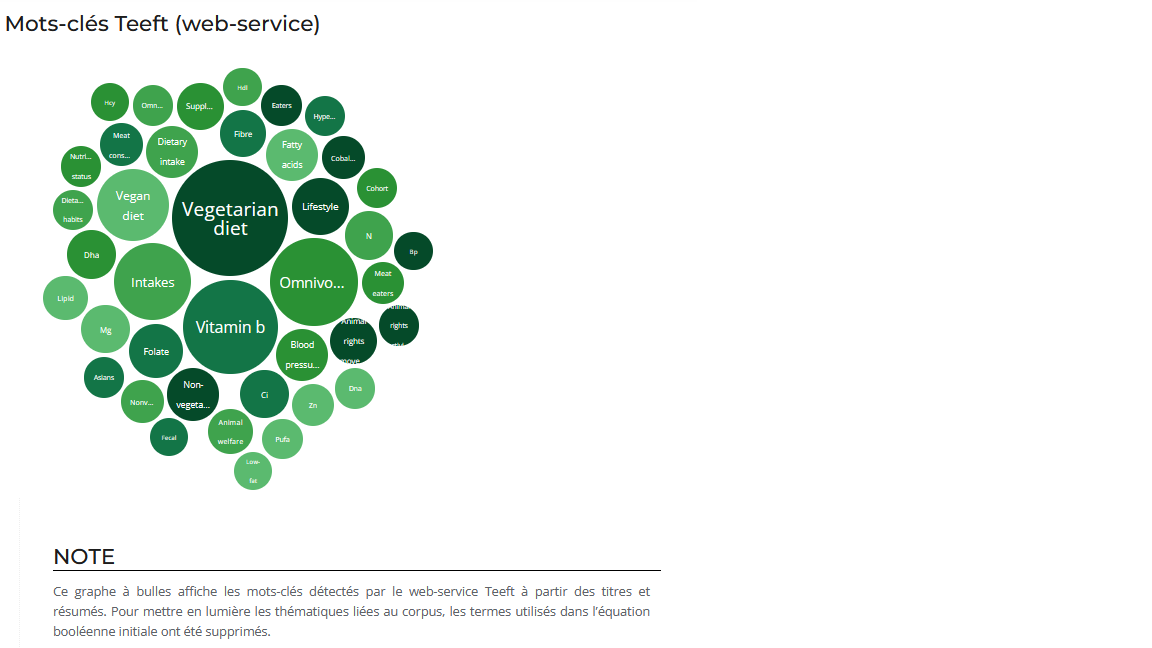

Graphes issus :
- du corpus Istex “Végane et Végétarien“. L’indexation a été réalisée sur le titre et le résumé. Profitez en pour naviguer dans l’ensemble du corpus et découvrez d’autres corpus scientifiques
- d’une étude réalisée pour la Direction des Données Ouvertes de la Recherche (DDOR) (Comptes rendus annuels d’activité des chercheurs CNRS 2020-2021). Le web service a traité le texte intégral Mots-clés extraits à partir du texte intégral en fonction des disciplines HAL