
Teeft - Extraction de termes d’un texte via Teeft
Le service web Teeft extrait, par défaut, les 5 termes les plus spécifiques d’un texte en anglais ou en français.
Il permet ainsi d’avoir une idée de ce dont il est question dans le texte.

Teeft commence par découper le texte en phrases, puis en tokens (des mots, typiquement).
Ensuite, il étiquette grammaticalement ces tokens (nom, adjectif, verbe, …) en prenant compte de la langue.
Il fait de ces tokens des termes, en les sélectionnant selon leur étiquette, et en rassemblant ceux qui se suivent (dans le même groupe nominal).
On enlève les nombres (les termes exclusivement constitués de chiffres), les mots vides (différents selon la langue), les termes trop courts, les termes trop longs (plus de 50 caractères), les termes alphanumériques contenant moins de lettres que de chiffres.
Puis on calcule une spécificité pour chaque terme, en se basant sur sa fréquence par rapport à sa fréquence d’apparition moyenne dans des textes génériques de la langue.
Enfin on filtre les termes pour ne garder que les plus spécifiques.
L’entrée est un texte en anglais ou en français (voir Variantes).
La sortie est une liste de 5 termes par défaut (Voir Variantes).
Le service Teeft originel pour l’anglais est utilisé pour enrichir des millions de documents de la base ISTEX.
Précautions :
- Assurez-vous que la langue du texte corresponde à la variante retenue.
- Idéalement le texte doit contenir plusieurs paragraphes.
Langues
- Anglais :
https://terms-extraction.services.istex.fr/v1/teeft/en - Français :
https://terms-extraction.services.istex.fr/v1/teeft/fr
Nombre de termes
Le paramètre nb est à adapter en fonction des besoins
Pour obtenir 10 termes, il est nécessaire de rajouter ?nb=10 à la fin de l’URL :
https://terms-extraction.services.istex.fr/v1/teeft/fr?nb=10
Nombres compris
Cette variante du web service extrait les termes les plus pertinents d’un texte en anglais ou en français, en conservant les chiffres : il fournit des termes contenant des chiffres (c’est important quand on a des formules chimiques, des grandeurs physiques, …).
La particularité de cette variante est d’encoder les chiffres avant de commencer le traitement et de les décoder ensuite, ce qui évite que les filtres les éliminent.
Ainsi, un multiterme tel que « 5 MW » est représenté en « inffivesup MW » et parvient jusqu’au décodage final.
Pour l’instant, la variante sur le français est en cours de développement.
https://terms-extraction.services.istex.fr/v1/teeft/with-numbers/en
https://terms-extraction.services.istex.fr/v1/teeft/with-numbers/fr
- Cuxac P., Kieffer N., Lamirel J.C. : SKEEFT: indexing method taking into account the structure of the document. 20th Collnet meeting, 5-8 Nov 2019, Dalian, China.
- Paquet
@ezs/teeft, cœur du programme: https://github.com/Inist-CNRS/ezs/tree/master/packages/teeft#readme
[{
"id": "https://fr.wikipedia.org/wiki/Mars_Exploration_Rover",
"value": "Mars Exploration Rover (MER) est une mission double de la NASA lancée en 2003 et composée de deux robots mobiles ayant pour objectif d'étudier la géologie de la planète Mars, en particulier le rôle joué par l'eau dans l'histoire de la planète. Les deux astromobiles ont été lancés au début de l'été 2003 et se sont posés en janvier 2004 sur deux sites martiens susceptibles d'avoir conservé des traces de l'action de l'eau dans leur sol. Chaque astromobile, piloté par un opérateur depuis la Terre, a alors entamé un périple en utilisant une batterie d'instruments embarqués pour analyser les roches les plus intéressantes (...)"
}][
{
"id": "https://fr.wikipedia.org/wiki/Mars_Exploration_Rover",
"value": [
"mars exploration rover mer",
"mission double",
"deux robots mobiles",
"planète mars",
"deux sites martiens susceptibles"
]
}
]

Vous avez un corpus et vous souhaitez en connaître le contenu ? En lançant Teeft sur vos données depuis Lodex, logiciel libre de visualisation, vous obtiendrez une indexation pour chaque document et des représentations graphiques liées.
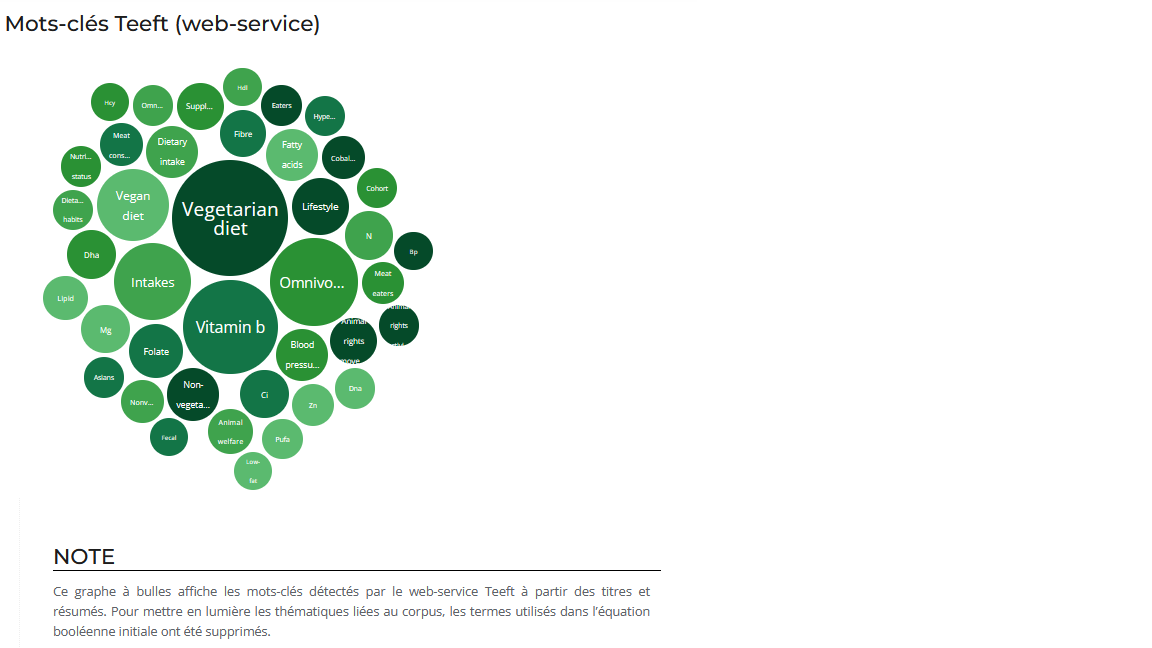

Graphes issus :
- du corpus Istex “Végane et Végétarien“. L’indexation a été réalisée sur le titre et le résumé. Profitez en pour naviguer dans l’ensemble du corpus et découvrez d’autres corpus scientifiques
- d’une étude réalisée pour la Direction des Données Ouvertes de la Recherche (DDOR) (Comptes rendus annuels d’activité des chercheurs CNRS 2020-2021). Le web service a traité le texte intégral Mots-clés extraits à partir du texte intégral en fonction des disciplines HAL