TermSuite - Extraction de termes d’un corpus
Ce web service s’appuie sur l’outil TermSuite pour faire une extraction terminologique à partir d’un corpus de textes en anglais ou en français.
La liste des 500 termes extraits par défaut contient les termes les plus spécifiques au corpus correspondant à tous les fichiers textes.
Cela permet d’avoir une idée des sujets abordés par l’ensemble des fichiers.
L’extraction terminologique à partir d’un corpus spécialisé est une première étape à la constitution d’un vocabulaire contrôlé sur un domaine particulier.
Le programme utilisé est TermSuite. Il effectue les traitements en 2 phases :
- Analyses linguistiques : segmentation du texte en mots, lemmatisation et étiquetage morphosyntaxique
- Extraction terminologique monolingue : détection d’occurrences de termes simples et complexes, normalisation et regroupement des termes en fonction de leurs variations, calcul de spécificité et filtrage statistique.
TermSuite calcule la spécificité (termhood) d’un candidat terme par rapport à un corpus de langue générale. Les termes ainsi sélectionnés sont renvoyés par spécificité décroissante.
L’entrée est un fichier .tar.gz contenant des fichiers .json en anglais ou en français (voir Variantes).
La sortie est une liste de 500 termes par défaut (voir Variantes). Chaque mot est précédé de son étiquette grammaticale (n pour nom, a pour adjectif, …). Chaque terme est associé à sa fréquence d’apparition dans le corpus.
Précaution
Assurez-vous que la langue des textes corresponde à la variante retenue.
- TermSuite
- Béatrice Daille.
Term Variation in Specialised Corpora: Characterisation, automatic discovery and applications.
Vol. 19. John Benjamins Publishing Company, 2017.
Notice - Damien Cram and Béatrice Daille.
Terminology Extraction with Term Variant Detection.
Proceedings of ACL-2016 System Demonstrations.
PDF - Jérôme Rocheteau and Béatrice Daille.
TTC TermSuite: A UIMA Application for Multilingual Terminology Extraction from Comparable Corpora.
Proceedings of the 5th International Joint Conference on Natural Language Processing, 2011.
PDF
Utilisation dans TDM Factory
Ce web service se lance sur :
- un corpus Istex au format targz
- un corpus au format CSV
- un corpus avec des fichiers textes, encodés en UTF8, dans un répertoire data, au format .tar.gz
Sélectionner le bon web service en fonction de la langue des textes.
Utilisation dans Lodex
Sélectionnez le web service dans le catalogue :
Précalcul : le web service traite le corpus dans sa globalité. Le résultat obtenu pour chaque document dépend des autres. Exemple pour la génération de clusters. On parlera de web service asynchrone
* Si vous avez des textes en anglais
Saisir cette URL https://data-termsuite.services.istex.fr/v1/en/minimal et sélectionner la colonne dédiée au texte en anglais.
Sauvegarder et lancer le traitement
* Si vous avez des textes en français
Saisir cette URL https://data-termsuite.services.istex.fr/v1/fr/minimal et sélectionner la colonne dédiée au texte en français.
Sauvegarder et lancer le traitement
* Si vous souhaitez paramétrer le nombre de termes de textes en anglais (ex : 10)
Saisir cette URL https://data-termsuite.services.istex.fr/v1/en/minimal?nb=10 et sélectionner la colonne dédiée au texte en anglais.
Sauvegarder et lancer le traitement
* Si vous souhaitez paramétrer le nombre de termes de textes en français (ex : 10)
Saisir cette URL https://data-termsuite.services.istex.fr/v1/fr/minimal?nb=10 et sélectionner la colonne dédiée au texte en français.
Sauvegarder et lancer le traitement
Langues
- anglais :
https://data-termsuite.services.istex.fr/v1/en/minimal - français :
https://data-termsuite.services.istex.fr/v1/fr/minimal
Nombre de termes
Le paramètre nb est à adapter en fonction des besoins. Par défaut, 500 termes sont renvoyés.
Pour obtenir 10 termes, il est nécessaire de rajouter ?nb=10 à la fin de l’URL :
https://data-termsuite.services.istex.fr/v1/en/minimal?nb=10
Ce web service ne traite pas des fichiers mais des corpus : ceci est un exemple de contenu d’un fichier d’un corpus
| Microbiology and Nitrogen Cycle in the Benthic Sediments of a Glacial Oligotrophic Deep Andean Lake as Analog of Ancient Martian Lake-Beds . Potential benthic habitats of early Mars lakes, probably oligotrophic, could range from hydrothermal to cold sediments. Dynamic processes in the water column (such as turbidity or UV penetration) as well as in the benthic bed (temperature gradients, turbation, or sedimentation rate) contribute to supply nutrients to a potential microbial ecosystem … | ==> | key: n: sediment spec:4.61 freq: 10 key: nn: proto-paratethys sea spec:4.56 freq: 9 key: a: glacial spec:4.46 freq: 7 key: n: mmes spec:4.46 freq: 7 key: a: tropical freq: 7 spec:4.46 |
PS: Techniquement, le service renvoie un JSON dont le champ value est l’identifiant du traitement:
[ { "id": "termsuite-en", "value": "gp8QhnnGb" } ]À partir de cet identifiant, on peut forger une requête vers https://data-termsuite.services.istex.fr/v1/retrieve-json pour récupérer le résultat.
Pour plus de détails, voir la démonstration.


Vous avez un corpus et vous souhaitez en connaître le contenu ?
En lançant TermSuite sur vos données depuis Lodex, logiciel libre de visualisation, vous obtiendrez, par défaut, la liste des 500 termes les plus spécifiques au corpus (il ne s’agit pas d’une indexation de chaque document) et des représentations graphiques liées.
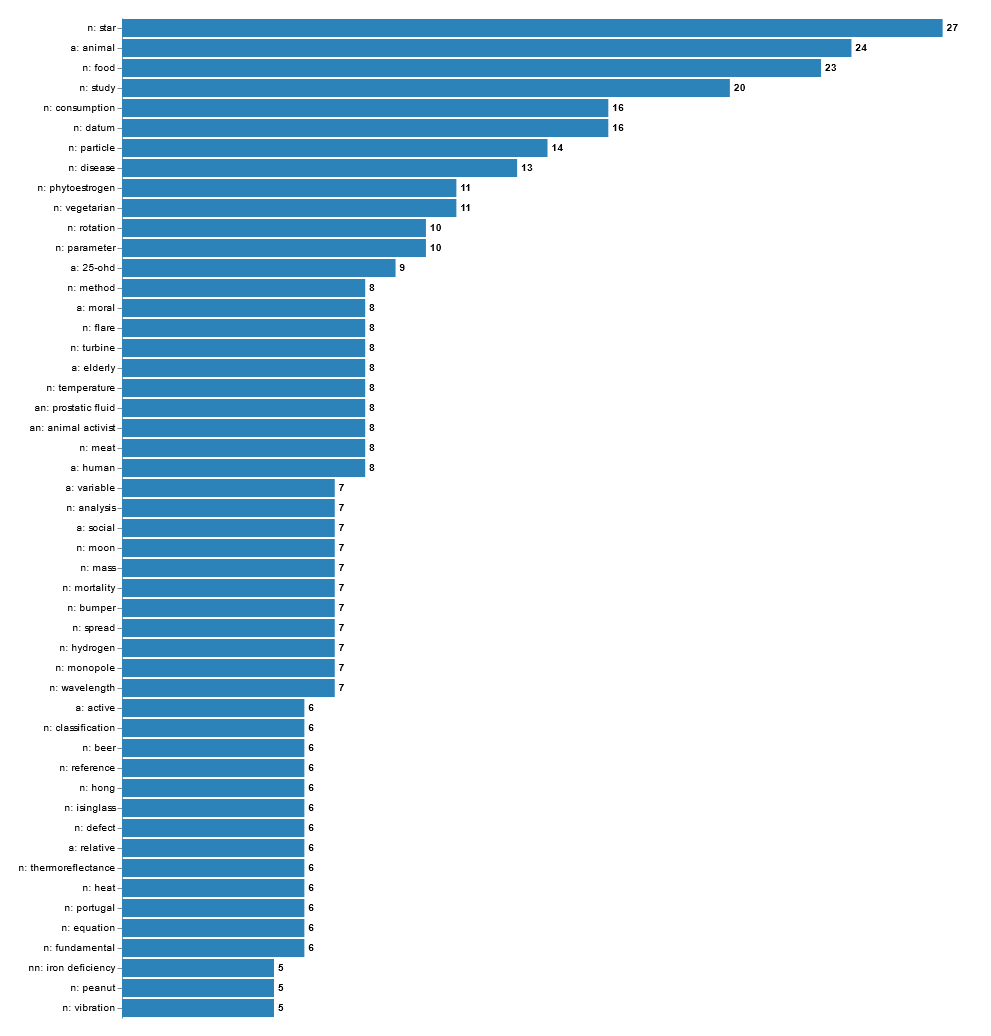
Pour obtenir le graphe ci-dessus dans Lodex, partie Graphiques :
- Sélectionner Donnée précalculée
- Choisir le précalcul existant
- Choisir la routine values-precomputed-nofilter/
- Sélectionner le format d’affichage Diagramme en barres et Décocher “Visible”