
genderDetect - Détection du genre de l’auteur
Ce web service retourne le genre d’un auteur ou d’une autrice à partir d’un prénom.
Les formats de prénoms pris en compte sont les suivants :
"prénom"
"prénom nom"
"prénom, nom"
Plusieurs sorties sont possibles :
- masculin : le prénom est masculin
- feminin : le prénom est féminin
- mixte_masculin : le prénom est mixte mais majoritairement porté par des hommes
- mixte_feminin : le prénom est mixte mais majoritairement porté par des femmes
- mixte : le prénom est mixte
- unknown : le prénom n’est pas dans nos données ou mal formé (ex: une initiale)
Notre liste “genre-prénom” est un mélange entre les données issues de la bibliothèque python gender-guesser et des données issues de la plateforme Kaggle :
- Gender-guesser : regroupe plus de 40000 prénoms internationaux avec le genre associé et
- Kaggle : regroupe les données des prénoms des bébés français et leur genre de 1900 à 2018 (INSEE)
Ces données ont été fusionnées dans un pré-traitement et enregistrées sous la forme d’un dictionnaire avec les prénoms en clé et les genres en valeurs :
{"Jean-Claude":"masculin", "Amke":"mixte_féminin", "Valentyne" : "unknown"}
Le genre d’un prénom peut être différent selon le pays. Ainsi nous avons fait le choix de sélectionner le genre le plus fréquent dans le monde.
- Bibliothèque python gender-guesser : https://github.com/lead-ratings/gender-guesser
- Plateforme Kaggle : https://www.kaggle.com/datasets/haezer/french-baby-names?select=national_names.csv
Article associé :
- Comment pré-traiter ses données pour utiliser le web service de détection de genre : voir onglet Utilisation, la rubrique “Pour aller plus loin”
Désambiguïsation d'auteurs via ORCID
Associer un identifiant ORCID à l’identifiant IDREF correspondant
Utilisation dans Lodex
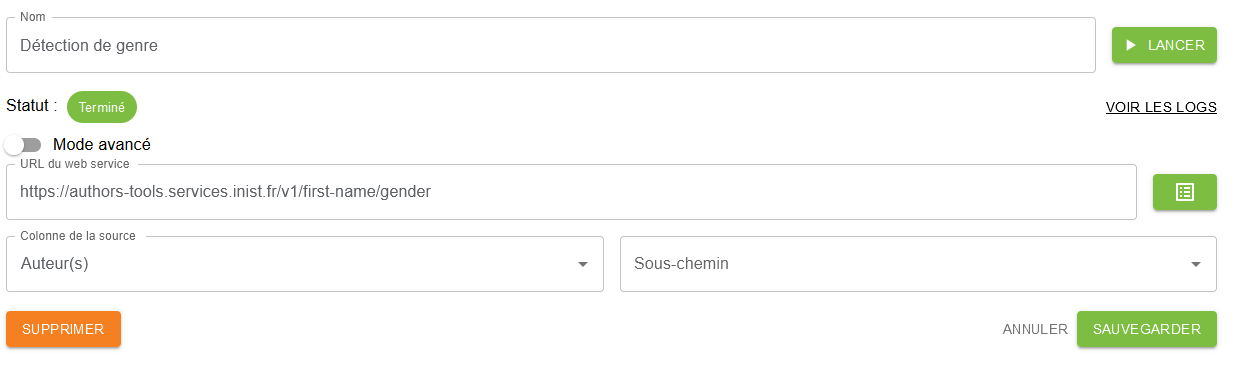
Sélectionnez le web service dans le catalogue :
Enrichissement : le web service traite chaque document l’un après l’autre. Exemple pour l’extraction de termes à partir du résumé. On parlera de web service synchrone.
Saisir cette URL https://authors-tools.services.istex.fr/v1/first-name/gender et sélectionner la colonne dédiée aux auteurs.
Sauvegarder et lancer le traitement
| Valentyne, Dupont | ==> | n/a |
| Amke | ==> | mixte_feminin |
| Seong-Eun Park | ==> | feminin |
| James A. | ==> | masculin |


Le Web Service de Détection du genre de l’auteur prend en entrée 3 formats spécifiques : “prénom”, “prénom nom” ou “prénom, nom”. Dans cet article, nous vous expliquons comment utiliser les recettes de Lodex pour lancer “Detect-Gender” sur des données diverses issues de CorHal, Istex ou encore du Web Of Science (WOS).
1) Cas n°1 : CorHal
Ces données sont issues de l’API CorHal. Pour les charger dans Lodex, utilisez le loader “JSON – Compatible API Conditor”.
Les prénoms des auteurs sont présents dans la colonne “authors”.
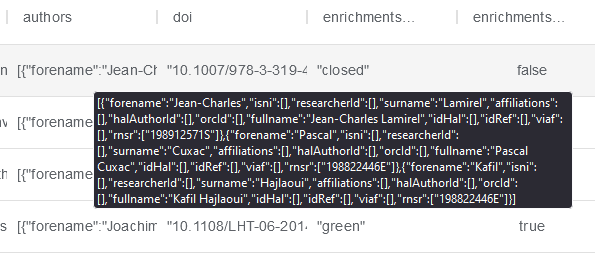
Une fois l’import fait, suivez les étapes suivantes pour générer une colonne comportant exclusivement les prénoms.
Allez dans les enrichissements, sélectionnez le Mode avancé et saisissez les lignes spécifiques ci-dessous :
[assign]
path = value
value = get("value.authors").map("forename")
Précisions sur le code :
- Le
get()permet de récupérer la valeur de la colonne « authors » - Le
map()permet de parcourir les éléments de “authors” et de récupérer “forename”

Une fois l’enrichissement fait, une nouvelle colonne comportant les prénoms est créée :
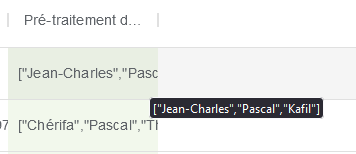
Vous pouvez alors lancer Detect-Gender
2) Cas n°2 : Istex
Dans ce cas, utilisez le loader spécifique pour Istex (“ZIP – résultat de dl.istex.fr”). Il n’y a pas de pré-traitement spécifique à faire, il suffit de lancer “Detect-Gender” sur la colonne “Auteur(s)”.
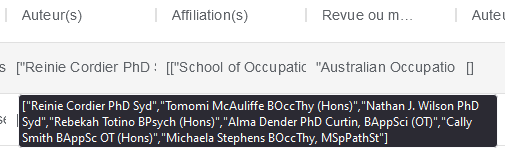
3) Cas n°3 : Web of Science
Pour les données du WoS, utilisez un loader en fonction du format des données. Dans notre cas, nous avons utilisé le loader “TSV – avec tabulations”.
Les noms prénoms des auteurs sont présents dans la colonne “AF”. Un pré-traitement est nécessaire pour sélectionner uniquement les prénoms.
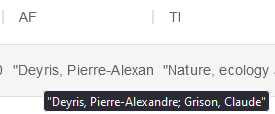
Sélectionnez le Mode avancé de l’enrichissement et saisissez les lignes suivantes :
[assign]
path = value
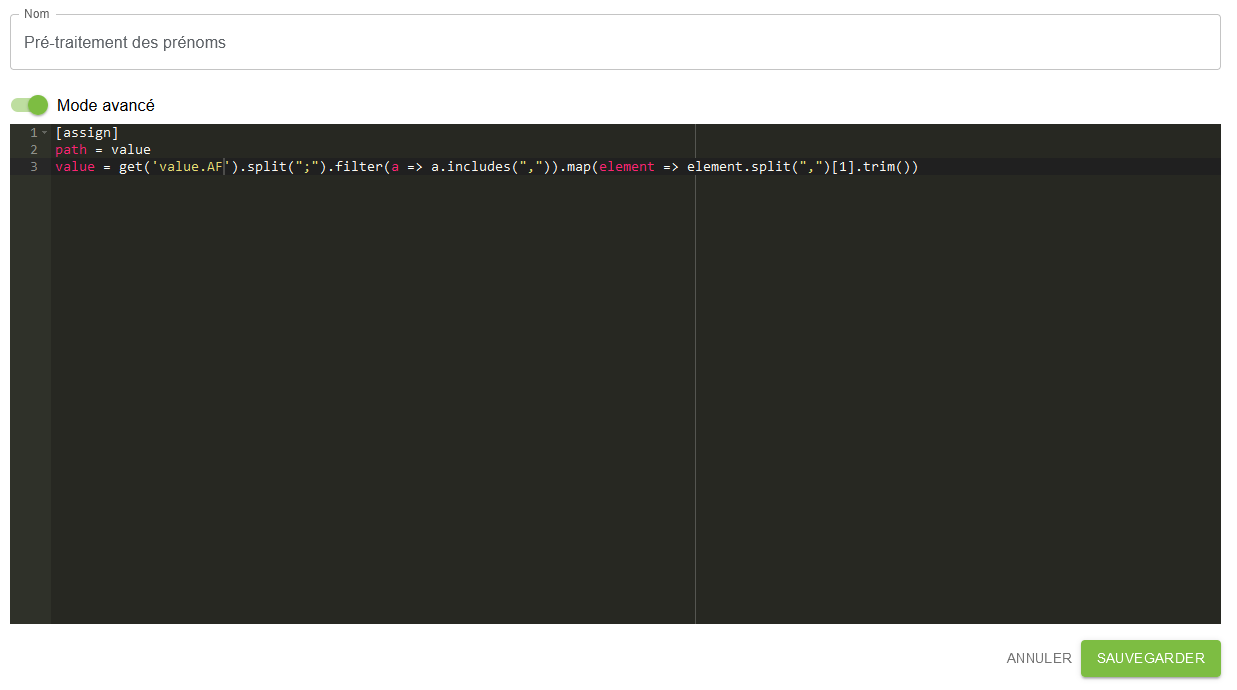
value = get("value.AF").split(";").filter(a => a.includes(",")).map(element => element.split(",")[1].trim())
Précisions sur le code :
- Le
get()permet de récupérer la valeur de la colonne “AF” - Le
split()permet de séparer les auteurs à chaque point-virgule, créant ainsi plusieurs éléments dans un tableau [“Nom1, Prénom1”, “Nom2, Prénom2”, “Nom3, Prénom3”, “Nom4”] - La dernière partie du code utilise
split()pour diviser chaque élément en un tableau de sous-chaînes à la virgule, et[1]permet de récupérer uniquement la sous-chaîne correspondant au “Prénom”. (Pour info : la première valeur est le nom qui a la valeur[0] - Enfin, le
trim()supprime les espaces en début et en fin de cette sous-chaîne.
Une nouvelle colonne de prénoms sans les noms de famille est ainsi créée :
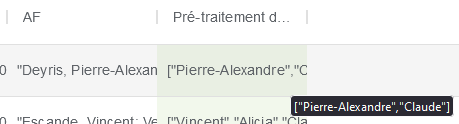
Vous pouvez alors lancer Detect-Gender
A noter que ce dernier traitement est aussi valable pour les données issues de ZOTERO.
Vous souhaitez réaliser une répartition des publications par genre ? Vous souhaitez voir la progression de cette répartition par genre ?
Vous souhaitez savoir si les membres de votre organisme privilégient un genre pour copublier ?
En lançant genderDetect sur vos données depuis Lodex, logiciel libre de visualisation, vous obtiendrez le genre des prénoms des auteurs et des représentations graphiques liées.
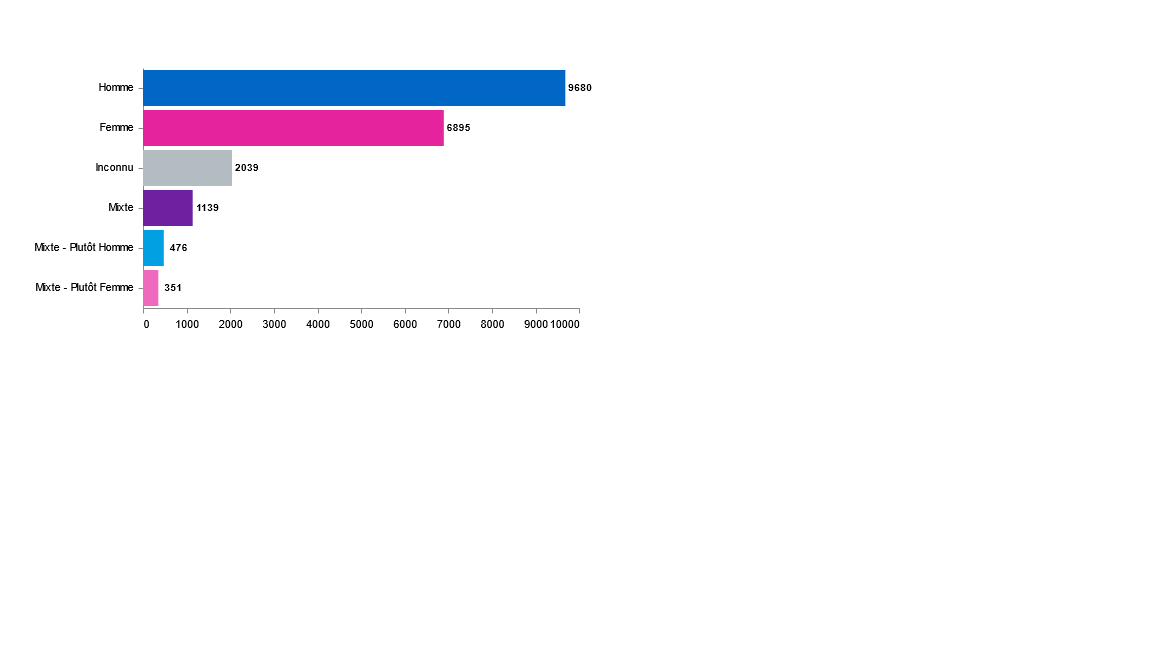
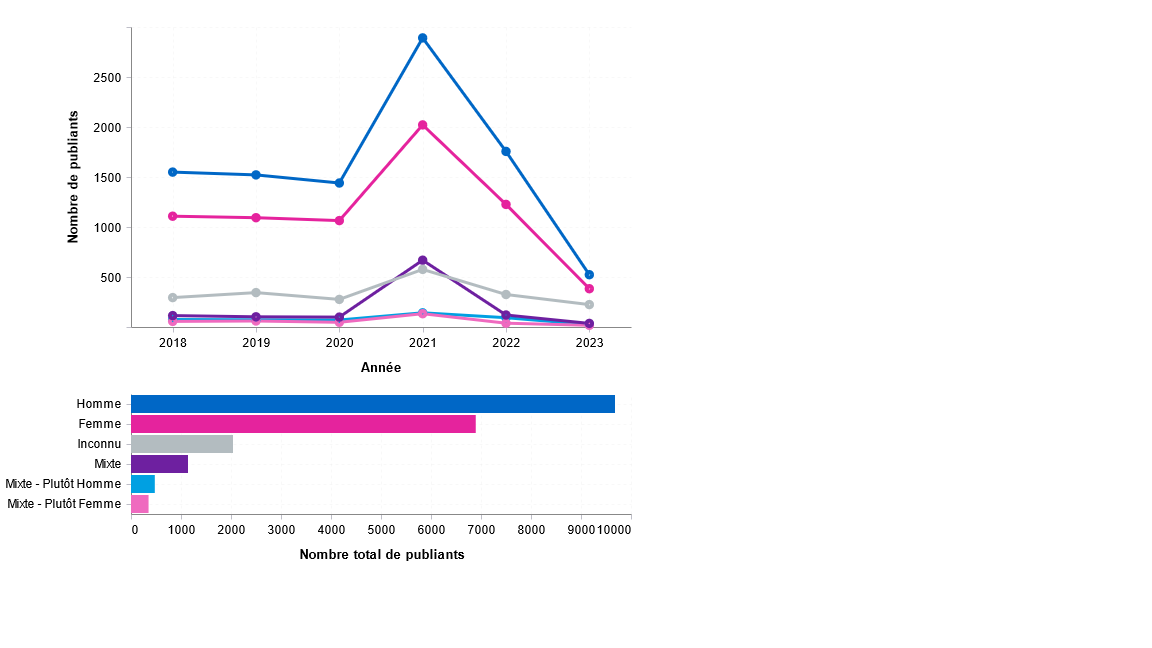
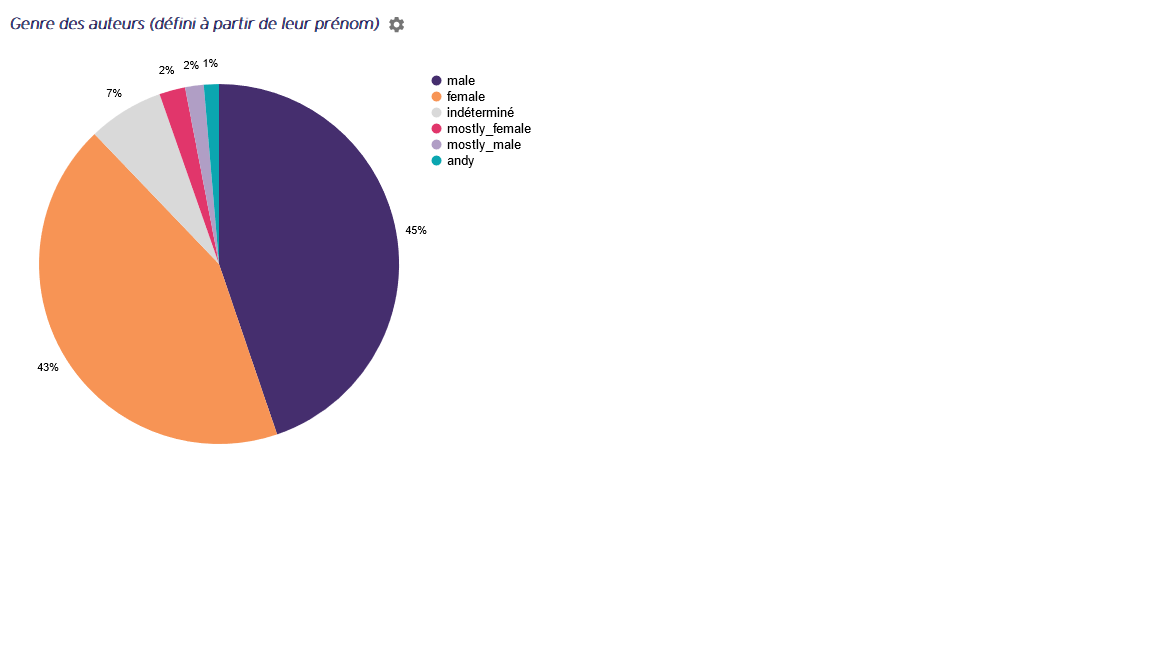
Graphes issus d’une étude réalisée pour l’I2BC (Institut de Biologie Intégrative de la Cellule — Production scientifique 2013-2023) et d’une étude réalisée pour l’Université Bordeaux Montaigne (Production scientifique 2018-2023)