
ldaClass - Extraction de thématiques d’un corpus
Ce web service traite non plus du texte mais des corpus de textes en anglais. En effet, le résultat obtenu pour chacun des documents dépend des autres.
Il extrait des thématiques d’un corpus : une thématique (ou topic) est caractérisée par dix mots. Une fois les thématiques extraites, chaque document se voit attribuer une ou plusieurs thématique(s).
Un LDA ou Allocation de Dirichlet latente est un algorithme non-supervisé de topic modeling. A l’aide de méthodes probabilistes, on construit aléatoirement des thématiques par des mots fréquemment rencontrés dans des textes. On réitère plusieurs fois cette attribution en modifiant les probabilités à chaque itération.
Ce web service prend en entrée un corpus au format .tar.gz. constitué d’un dossier compressé contenant un ensemble de fichiers json.
Chaque fichier json doit contenir à minima un champ value : c’est l’ensemble de ces champs du corpus qui est pris en entrée par ce service web.
Pour la sortie, le champ “value” de chaque document contient un champ “topics” constitué de 1 à 20 topics (généralement entre 1 et 3). Chaque topic contient un champ “words”, composé d’une liste de 10 mots (avec leur poids associé par rapport au topic) les plus caractéristiques du topic, ainsi qu’un champ “weight” qui correspond au poids associé au sujet dans le document. Seules les thématiques suffisamment probables sont retournées.
Le champ “value” contient également un champ “best_topic” qui contient le topic possédant le plus grand poids. Voir l’exemple dans “Utilisation” pour une meilleure visualisation de cette sortie.
Quant au nombre total de topics présents dans le corpus, il est déterminé automatiquement par défaut. Il peut être ajusté en fonction de la spécificité de votre corpus (voir la partie Variantes). Plus un corpus est spécialisé, plus le nombre théorique de topic doit être faible.
Un document considéré comme du bruit ne sera pas pris en compte par le modèle et la valeur retournée sera n/a.
Un modèle est créé à chaque utilisation : une optimisation des paramètres est incluse dans le code pour s’adapter à chaque corpus.
Cependant, la cohérence et l’exhaustivité des thématiques doivent être vérifiées à chaque utilisation.
Précaution
Le web service fonctionne uniquement sur des textes en anglais.
Sur des textes courts, comme les titres, les résultats ne sont pas garantis.
S’il y a peu de document (moins de 200), il est recommandé de fixer un petit nombre de topics (choisi par l’utilisateur)
Résultats bruts
Pour obtenir les résultats bruts du traitement, l’URL à utiliser est :
https://data-computer.services.istex.fr/v1/lda
Représentations graphiques
L’URL suivante, à lancer depuis Lodex dans la partie dédiée aux précalculs, permet la représentation graphique du traitement :
https://data-computer.services.istex.fr/v1/lda-segment
Nombre de topics
Le paramètre nbTopic (nombre de Topic) est facultatif. Par défaut, il est déterminé automatiquement
Pour obtenir 8 thématiques, il est nécessaire de rajouter ?nbTopic=8 à la fin de l’URL :
https://data-computer.services.istex.fr/v1/lda?nbTopic=8
ou
https://data-computer.services.istex.fr/v1/lda-segment?nbTopic=8
Documentation de la bibliothèque python Gensim sur la constitution d’un LDA : https://radimrehurek.com/gensim/auto_examples/tutorials/run_lda.html#sphx-glr-auto-examples-tutorials-run-lda-py.
Extraction de termes d'un texte via Teeft
Utilisation dans TDM Factory
Ce web service se lance sur :
- un corpus au format CSV avec du texte en anglais
- un corpus Istex au format targz avec du texte en anglais
Utilisation dans Lodex
Sélectionnez le web service dans le catalogue :
Précalcul : le web service traite le corpus dans sa globalité. Le résultat obtenu pour chaque document dépend des autres. Exemple pour la génération de clusters. On parlera de web service asynchrone
* Si vous souhaitez paramétrer le nombre de topics
Saisir cette URL https://data-computer.services.istex.fr/v1/lda?nbTopic=8 et sélectionner la colonne dédiée au texte anglais.
Sauvegarder et lancer le traitement
* Si vous souhaitez réaliser une représentation graphique
Saisir cette URL https://data-computer.services.istex.fr/v1/lda-segment et sélectionner la colonne dédiée au texte anglais.
Sauvegarder et lancer le traitement
- sélectionner le pré-calcul concerné
- choisir la routine : segments-precomputed-nofilter
- sélectionner la colonne du label : source et la colonne de la valeur : weight
- choisir l’affichage : groupement de diagrammes à barres (pour les versions de Lodex supérieures à 14)
* Si vous souhaitez paramétrer le nombre de topics dans la représentation graphique
Saisir cette URL https://data-computer.services.istex.fr/v1/lda-segment?nbTopic=8 et sélectionner la colonne dédiée au texte anglais.
Sauvegarder et lancer le traitement
Ce service web ne traite pas des fichiers mais des corpus : ceci est un exemple de contenu d’un fichier d’un corpus.
| Zinc (Zn), iron (Fe), magnesium (Mg), and calcium (Ca) in chickpea seed are important constituents in vegetarian diets. The aim was to investigate associations of these nutrients in different chickpea (Cicer arietinum L.) cultivars with phytic acid (PA), another naturally occurring constituent of grain that may influence the bioavailability of mineral micronutrients. Chickpea was grown at Saskatoon and Swift Current, SK, in 2002 and 2003, representing dryland production from high-yielding locations in western Canada. Minerals were measured by atomic absorption spectroscopy; PA was measured using high-performance anion-exchange conductivity detection methodology… | ==> | topic_5: word: diet word_weight: 0.019507904 word: vegetarian word_weight: 0.019629745 … topic_8: word: study word_weight: 0.016340619 word: vegetarian word_weight: 0.011359757 … |
PS : Il s’agit de la sortie brute du traitement, et non celle obtenue dans Lodex.


Vous avez un corpus et vous souhaitez en connaître le contenu ?
En lançant ldaClass (https://data-computer.services.istex.fr/v1/lda-segment) sur vos données depuis Lodex, logiciel libre de visualisation, vous obtiendrez entre 10 et 20 classes caractérisées par 10 mots-clés et des représentations graphiques liées.
Pour réaliser le premier graphe :
- sélectionner le pré-calcul concerné
- choisir la routine : segments-precomputed-nofilter
- sélectionner la colonne du label : target et la colonne de la valeur : weight
- choisir l’affichage : groupement de diagrammes à barres
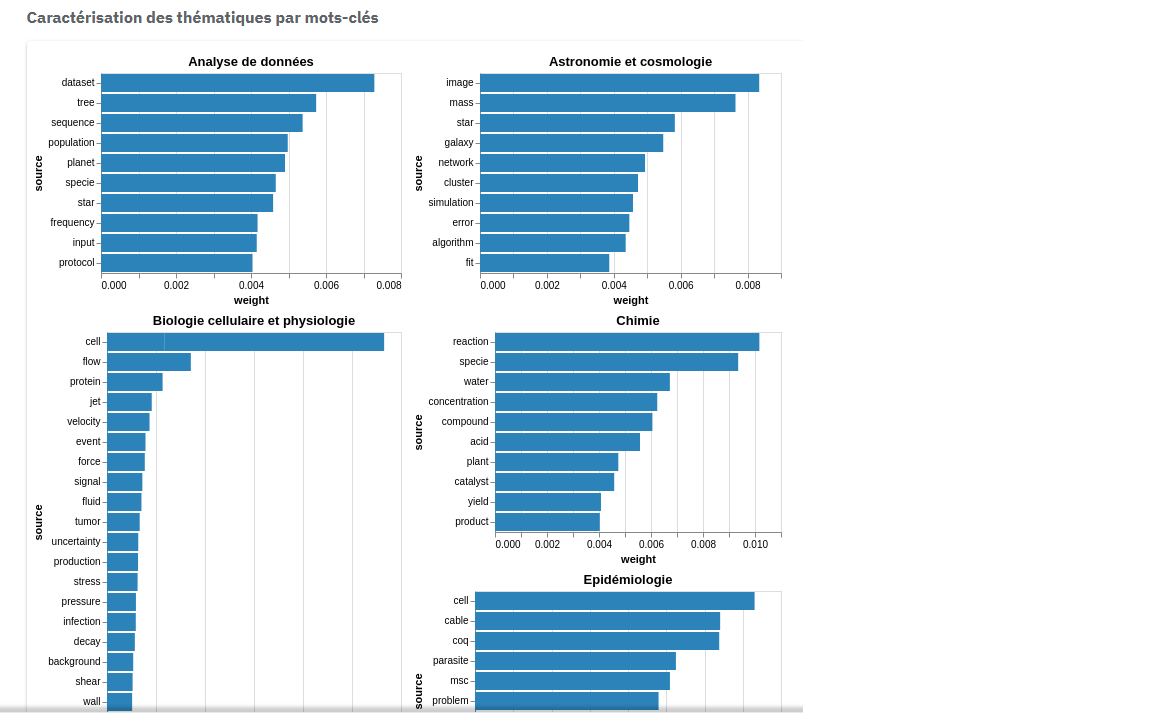
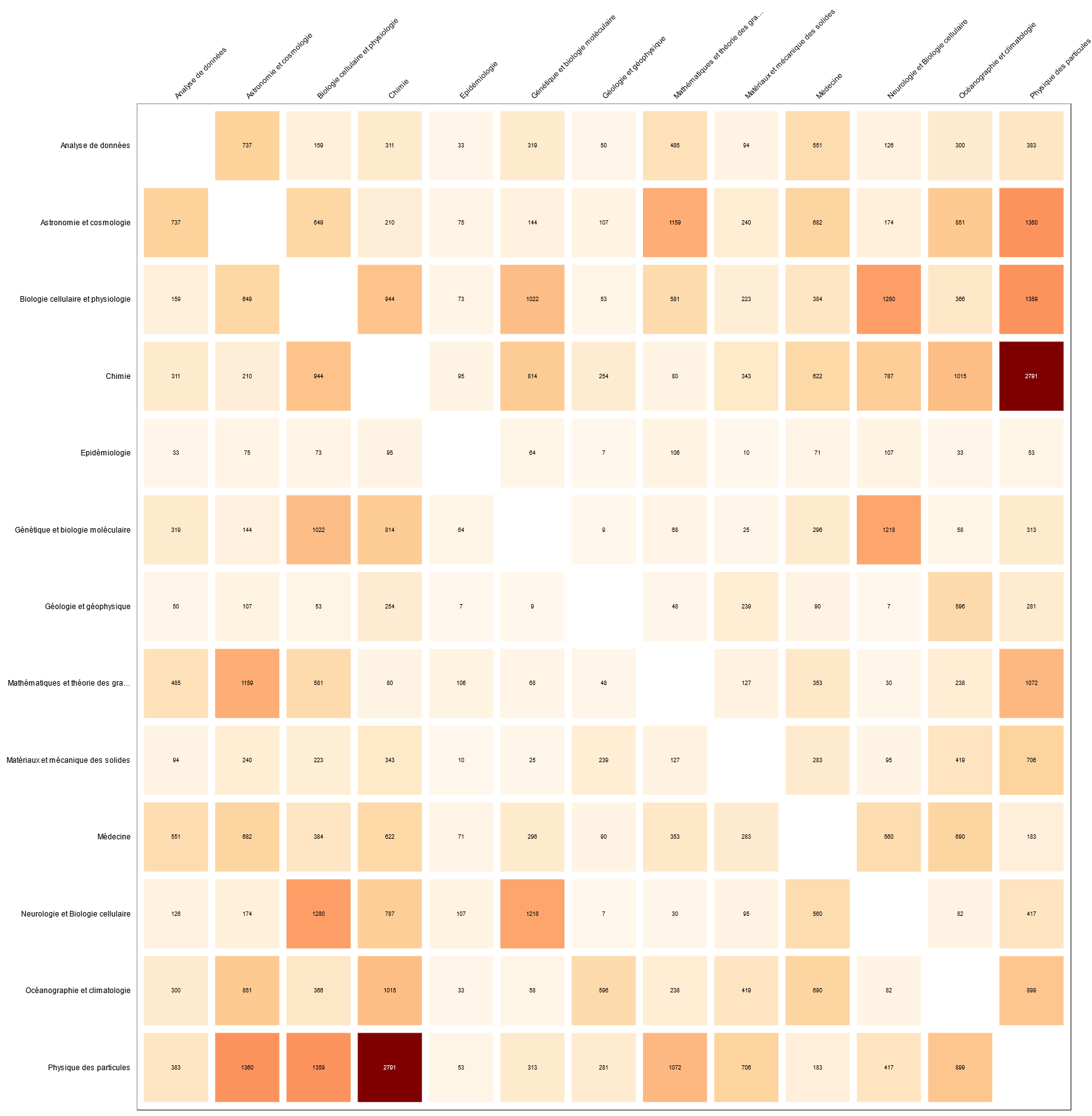
Graphes issus d’une étude réalisée pour la Direction des Données Ouvertes de la Recherche (DDOR) (Comptes rendus annuels d’activité des chercheurs CNRS 2020-2021). Le web service a traité le texte intégral des publications scientifiques.