
entityTag - Extraction d’entités nommées (Personnes, Localisations, Organismes)
Ce web service extrait trois types entités nommées. Deux variantes existent : la première fonctionne sur des textes français et anglais, la seconde fonctionne sur des textes en anglais uniquement.
Les trois champs en sortie sont :
– “PER” : Personnes, y compris les personnages fictifs.
– “LOC” : Lieux comme les pays, villes, états, les chaînes de montagnes, les plans d’eau, etc.
– “ORG” : Entreprises, agences, institutions, etc.
Les deux modèles ont été entraînés en partant de zéro et en utilisant la bibliothèque PyTorch. Toutes les données d’entraînement des modèles sont disponibles sur notre dépôt git ws-data, dédié aux données d’entraînement et d’évaluation.
La f-mesure de ces modèles varie entre 0.85 et 0.9 en fonction des corpus.
Corpus d’évaluation
Les modèles ont été évalués sur 2 jeux de données différents (3 pour le modèle multilingue). L’ensemble des résultats par corpus peut être retrouvé sur notre dépôt git ws-data, dédié aux données d’entraînement et d’évaluation.
Les sous-ensembles français et anglais du corpus wikiner ayant servi à l’entraînement du modèle sont disponibles à l’adresse suivante :
https://www.ortolang.fr/market/corpora/tdm-eval-dataset-ner
URL du dépôt git dédié à l’entraînement de ce modèle : ws-data.
Utilisation dans TDM Factory
Ce web service se lance sur :
- un corpus au format CSV avec du texte en anglais ou en français
- un corpus Istex au format targz avec du texte en anglais ou en français
- un corpus de textes au format targz en anglais ou en français
- un article au format PDF avec du texte en anglais ou en français
- un article au format txt avec du texte en anglais ou en français
Utilisation dans Lodex
Sélectionnez le web service dans le catalogue :
Enrichissement : le web service traite chaque document l’un après l’autre. Exemple pour l’extraction de termes à partir du résumé. On parlera de web service synchrone.
* Si vous avez des textes anglais et français
Saisir cette URL https://person-ner.services.istex.fr/v1/tagger et sélectionner la colonne dédiée au texte.
Sauvegarder et lancer le traitement
Pour récupérer la valeur souhaitée : GET et le nom du champ dont vous voulez extraire la donnée
- PER pour les noms de personnes
- LOC pour les noms géographiques
- ORG pour les noms d’organismes
* Si vous avez des textes anglais uniquement
Saisir cette URL https://person-ner.services.istex.fr/v1/tagger-en et sélectionner la colonne dédiée au texte en anglais
Sauvegarder et lancer le traitement
Pour récupérer la valeur souhaitée : GET et le nom du champ dont vous voulez extraire la donnée
Modèle multilingue
Pour le modèle multilingue, l’URL à utiliser est https://person-ner.services.istex.fr/v1/tagger
Modèle pour des textes anglais
Sur des textes uniquement écrits en anglais, l’URL à utiliser est https://person-ner.services.istex.fr/v1/tagger-en
| Jean Dupont assiste au festival de Cannes sur la côte d’Azur. | ==> | PER: Jean Dupont LOC: côte d’Azur ORG: MISC: festival de Cannes |
| Python is widely used in data science. Bob R. uses it ; he works for the CNRS | ==> | PER: Bob R. LOC: ORG: CNRS |


Vous avez un corpus et vous souhaitez en connaître le contenu ?
En lançant entityTag sur vos données depuis Lodex, logiciel libre de visualisation, vous obtiendrez pour chaque document des termes associés à différentes entités nommées (Personne, Localisation, Organisme et Divers) et des représentations graphiques liées.
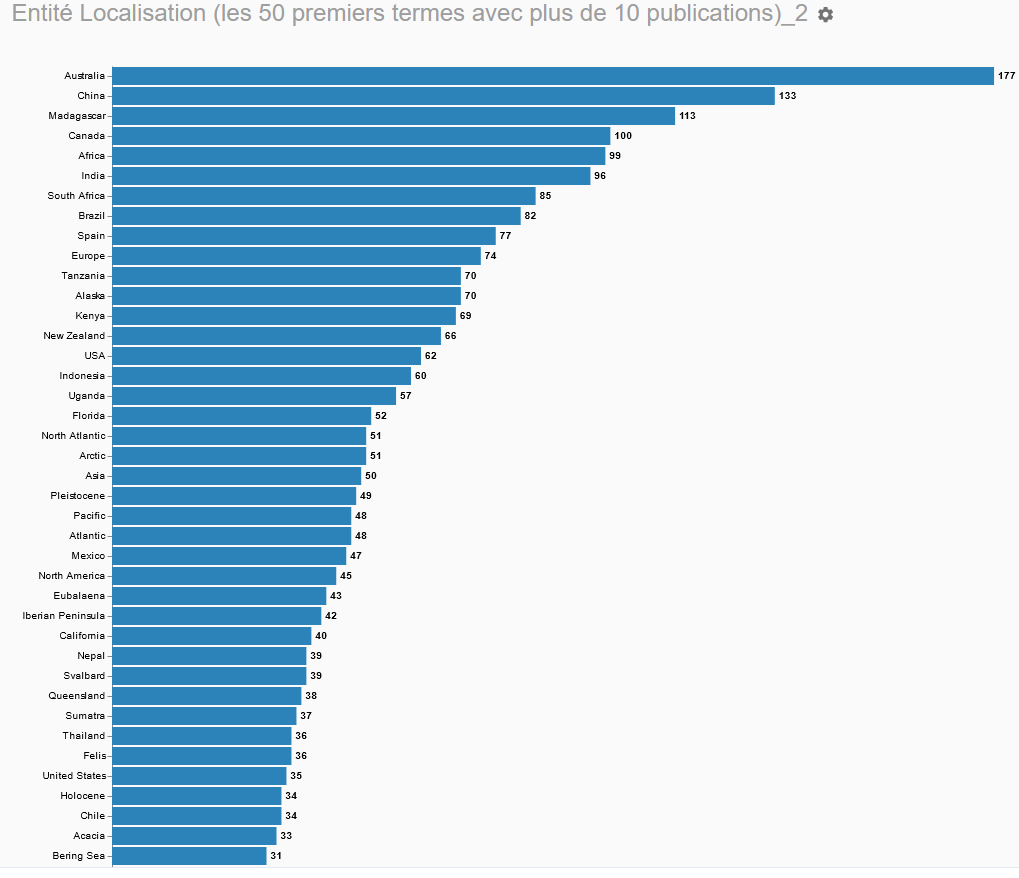
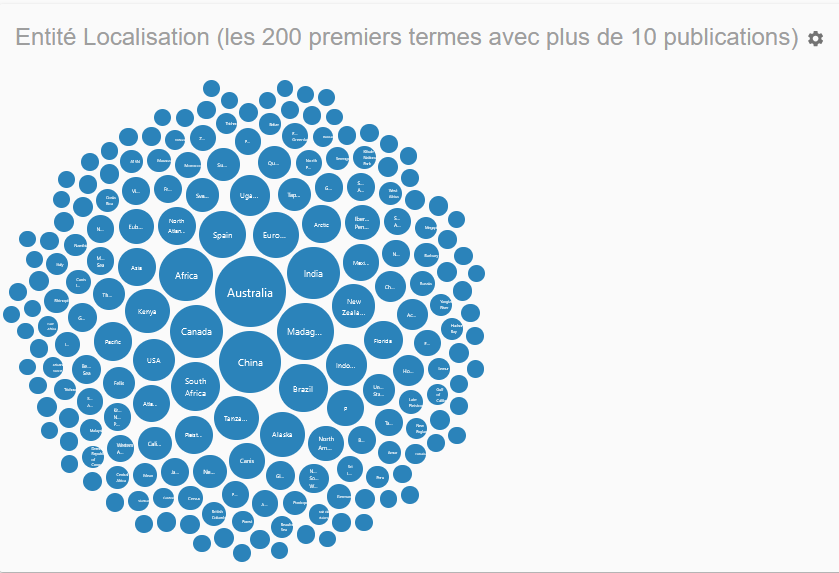
Graphes réalisés à partir des données du corpus Istex “Biodiversité”. Sont affichées les valeurs supérieures à 10.
Profitez en pour naviguer dans l’ensemble du corpus
et découvrez d’autres corpus scientifiques