
datatableExtract - Détection et extraction de tableaux dans un article scientifique
Niveau d'utilisation :
Débutant
Niveau de validation :
Expérimental
Objectif
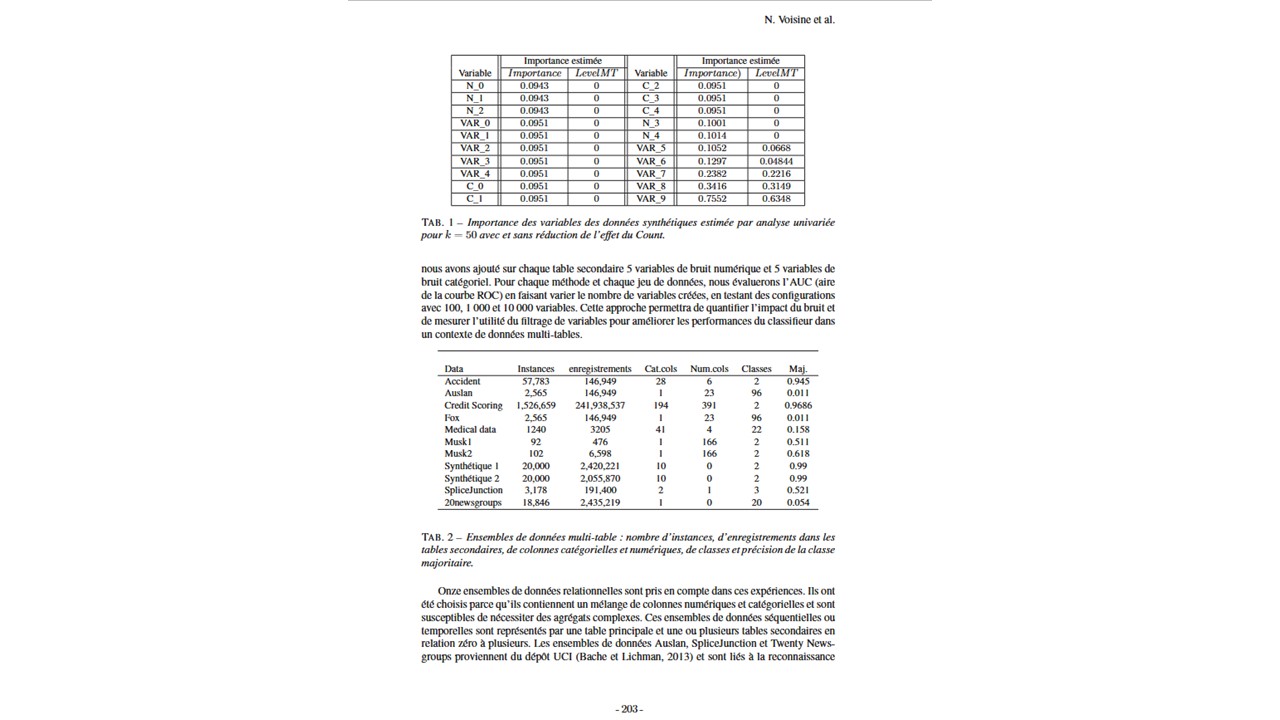
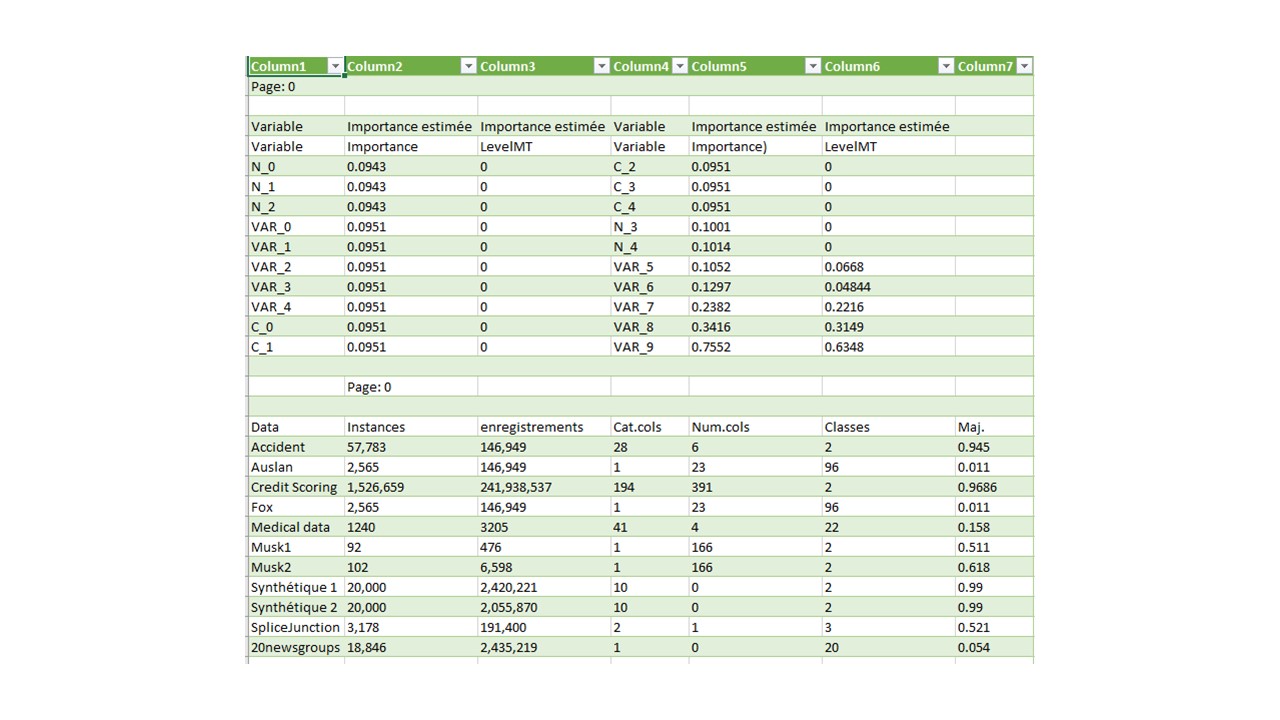
Ce web service extrait les différents tableaux présents dans des documents au format PDF d’un corpus, et renvoie le résultat sous format json ou csv.
Méthode
L’extraction se fait principalement via tesseractOCR, implémenté via la bibliothèque python img2table.
Variantes
Langues
- Anglais (par défaut) :
http://data-table.services.istex.fr/v1/table-extraction - Français :
http://data-table.services.istex.fr/v1/table-extraction?lang=fra
Formats
- Format ligne (par défaut) :
http://data-table.services.istex.fr/v1/table-extraction - Autres formats :
http://data-table.services.istex.fr/v1/table-extraction?format=dict
Plus d’informations sur les choix d’options disponibles sur https://github.com/Inist-CNRS/web-services/tree/main/services/data-table
Références
img2table : https://github.com/xavctn/img2table
Présent sur TDM Factory
LIEN VERS TDM FACTORY
Aller à TDM Factory
Utilisation dans TDM Factory
Ce web service se lance sur un document au format PDF texte (Le PDF format image ne fonctionne pas).
Absent de Lodex
Traitement
 |
==> |  |

