
pascalFrancisClass - Classification en domaines scientifiques Pascal-Francis
Le web service classe automatiquement des documents scientifiques en anglais dans le plan de classement Pascal (Sciences, Techniques et Médecine) ou Francis (Sciences Humaines et Sociales).
Après traitement, chaque document possède un domaine scientifique homogène, dans la mesure où les données de départ ont permis ce traitement.
Le classifier applique une démarche d’apprentissage supervisé qui prédit des domaines en s’appuyant sur un corpus de documents contenant les domaines à prédire. Le corpus d’entraînement utilisé est constitué de notices bibliographiques extraites des bases de données Pascal/Francis
Le taux de confiance est supérieur à 0.9.
Précautions :
- Le web service fonctionne uniquement sur du texte anglais.
- Fonctionnant avec de l’apprentissage, il est nécessaire d’utiliser ce web service sur des phrases pour un résultat plus fiable.
Il est possible de varier la profondeur de la prédiction dans le plan de classement. Celle-ci est par défaut fixée à 3. Pour en changer, il suffit de suffixer l’URL par ?deep=X ou X varie entre 1 et 3.
Exemple: https://domains-classifier-2.services.istex.fr/v1/en/classify?deep=2
Article associé
Web service “Classification en domaines scientifiques Pascal-Francis” : cascade de modèles pour l’affectation de domaine(s) scientifique(s) aux publications scientifiques : voir onglet Utilisation, la rubrique “Pour aller plus loin”.
Utilisation dans Lodex
Sélectionnez le web service dans le catalogue :
Enrichissement : le web service traite chaque document l’un après l’autre. Exemple pour l’extraction de termes à partir du résumé. On parlera de web service synchrone.
* Si vous souhaitez tous les niveaux du plan de classement
Saisir cette URL https://domains-classifier.services.istex.fr/v1/en/classify et sélectionner la colonne dédiée au texte en anglais.
Sauvegarder et lancer le traitement
* Si vous souhaitez uniquement le niveau 1 du plan de classement
Saisir cette URL https://domains-classifier-2.services.istex.fr/v1/en/classify?deep=1 et sélectionner la colonne dédiée au texte en anglais.
Sauvegarder et lancer le traitement
| Planck 2015 results. XIII. Cosmological parameters. We present results based on full-mission Planck observations of temperature and polarization anisotropies of the CMB. These data are consistent with the six-parameter inflationary LCDM cosmology. From the Planck temperature and lensing data, for this cosmology we find a Hubble constant, H0= (67.8 +/- 0.9) km/s/Mpc, a matter density parameter Omega_m = 0.308 +/- 0.012 and a scalar spectral index with n_s = 0.968 +/- 0.006. (We quote 68% errors on measured parameters and 95% limits on other parameters.) Combined with Planck temperature and lensing data, Planck LFI polarization measurements lead to a reionization optical depth of tau = 0.066 +/- 0.016… | ==> | id: 001 value: Sciences exactes et technologie confidence: 1.0000057220458984 rang: niveau1 id: 001E value: Terre, océan, espace confidence: 0.9999549388885498 rang: niveau2 id: 001E03 value: Astronomie confidence: 1.0000100135803223 rang: niveau3 |


Cascade de modèles pour l’affectation de domaine(s) scientifique(s) aux publications scientifiques
L’attribution de domaine(s) scientifique(s) est une activité nécessaire à la caractérisation et donc à l’identification des contenus des bibliothèques numériques.
Les méthodes actuelles basées sur l’apprentissage supervisé permettent de tirer parti de fonds documentaires pour lesquels il existe des données enrichies.
L’Inist-CNRS qui a publié des bases de données bibliographiques (bases Pascal et Francis) pendant de nombreuses années dispose de ce type de données analysées de façon semi-automatique par des documentalistes spécialisés dans chacun des domaines de la science.
Dans le souci de mettre à disposition des services à forte valeur ajoutée appliqués aux réservoirs de publications scientifiques, l’INIST-CNRS a entrepris de bâtir et de proposer un web service de classification de textes en domaine(s) scientifique(s) à base d’apprentissage.
Le web service pascalFrancisClass applique une démarche supervisée en apprenant à prédire des domaines en s’appuyant sur un corpus de documents contenant les catégories à prédire à savoir un code domaine du plan de classement utilisé à l’Inist-CNRS (exemple, “002A05” représente l’étiquette du domaine “microbiologie”).
L’objectif est d’apprendre et capturer dans un modèle la « relation » entre des mots et des codes de classement pour pouvoir prédire ces codes de classement sur de nouveaux textes. Au sein d’un modèle, les mots sont représentés sous la forme de vecteurs denses de type embeddings (plongement de mots) construits à partir de la bibliothèque d’apprentissage de représentation des mots et de classification de textes FastText (https://fasttext.cc/).
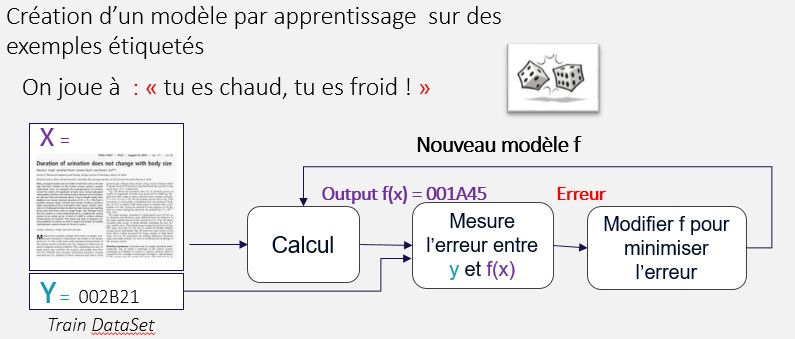
Figure 1 : le processus d’apprentissage
De façon théorique, l’apprentissage cherche à déterminer une équation mathématique qui permette de déduire Y à partir de paramètres Xn (1 à n). Il dispose pour cela d’exemples où Y existe, fait une prédiction en fixant Xn, mesure son erreur et adapte ses paramètres en fonction de l’ erreur. Le cycle est répété tant que l’approximation la plus juste n’est pas atteinte (i.e. la moins erronée).
Expérimentation
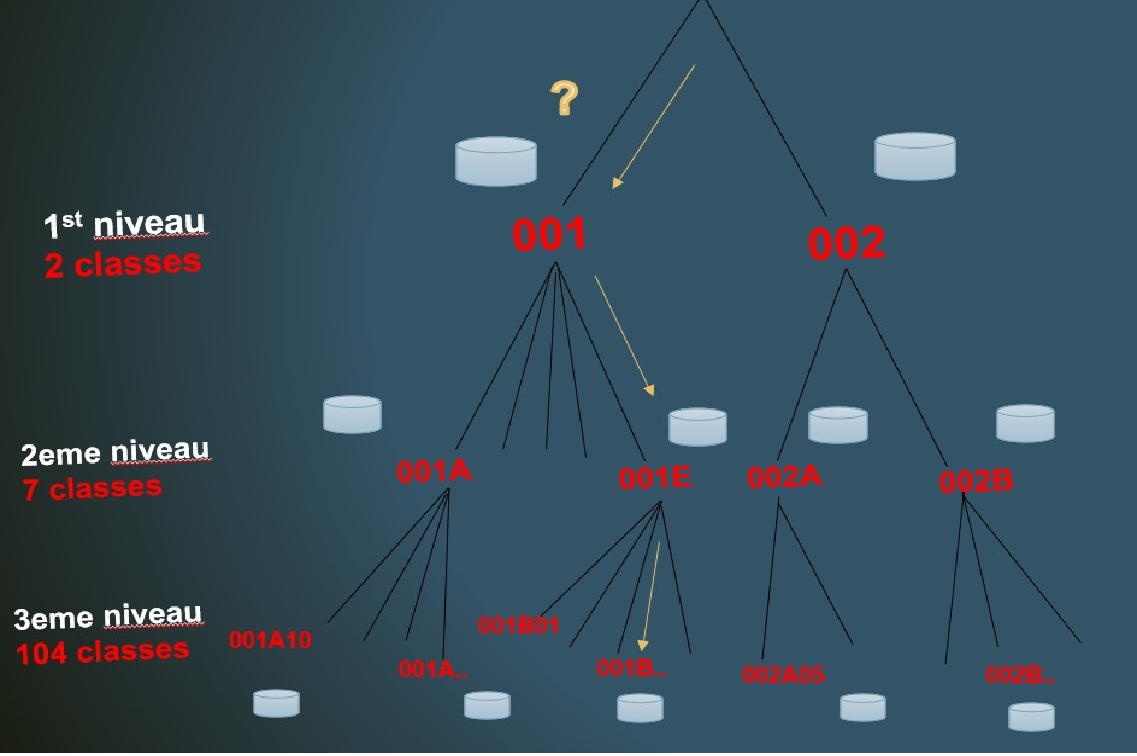
L’originalité de l’approche tient au fait qu’elle met en œuvre non pas un mais plusieurs modèles. Ces modèles sont construits par entraînement sur une série de corpus étiquetés chacun extrait sur la base de codes domaines. Chaque nœud de l’arborescence du plan de classement est associé à un modèle qui est chargé de prédire le sous-domaine du niveau inférieur.
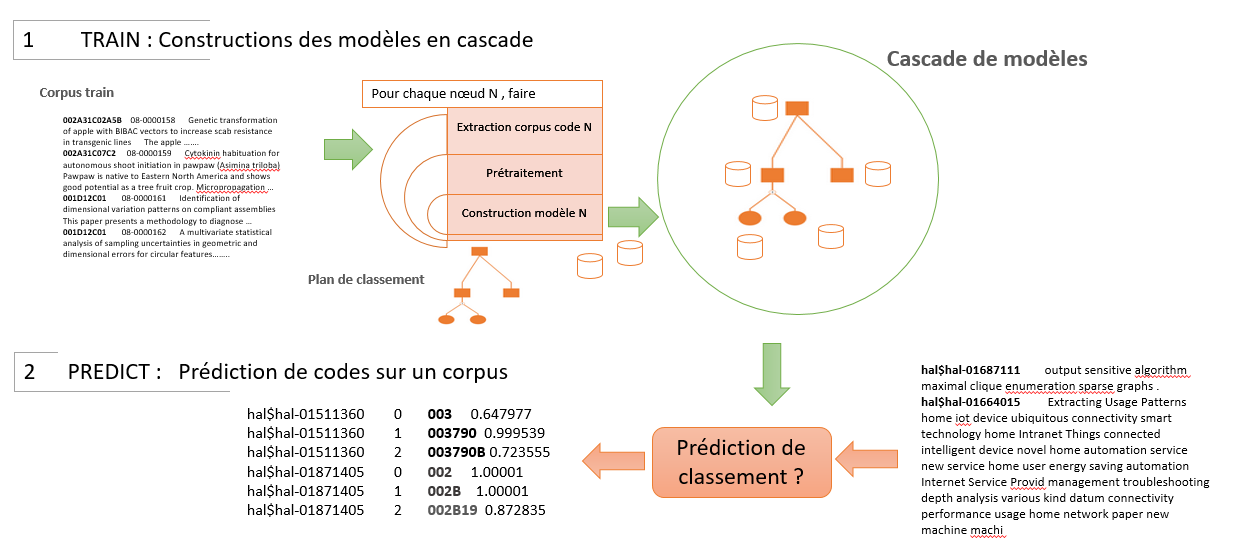
Figure 2: fonctionnement en apprentissage et en prédiction
Le corpus d’entraînement utilisé contient des notices bibliographiques (environ 5M de titres et résumés en langue anglaise) extraites de la base de données Pascal/Francis. (https://pascal-francis.inist.fr/cms/?lang=fr). Dans le détail, on compte 420K notices issues de la base SHS Francis et 4.9M issues de la base sciences exactes et médecine Pascal.
Les domaines à prédire sont issus d’un plan de classement documentaire, structure de connaissance qui présente une organisation hiérarchique en domaines et sous- domaines scientifiques. Les plans de classement utilisés pour la mise au point sont ceux des bases Pascal/Francis. (https://pascal-francis.inist.fr/vibad/index.php?action=classificationList&lang=fr).
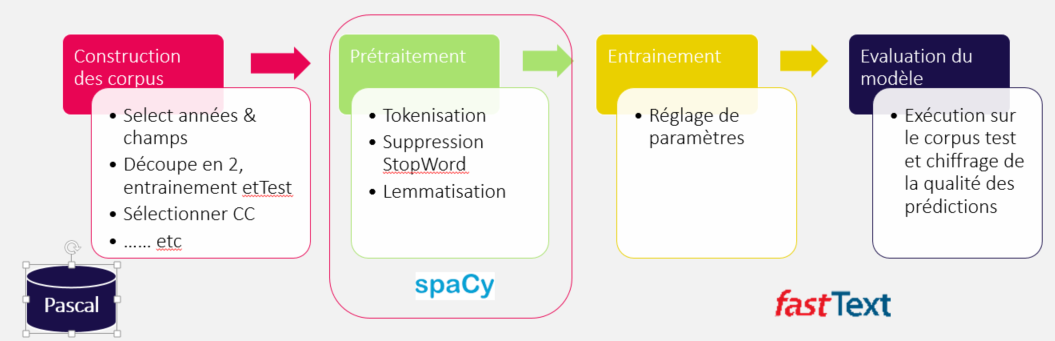
Figure 3 : Etapes de construction d’un modèle
L’expérience commence classiquement par une étape de préparation de corpus comme le montre la figure 3. Le corpus initial est séparé en corpus d’entraînement et corpus de test selon une proportion de 30/70. Des étapes traditionnelles telles que la suppression de stopwords et la POStag / lemmatisation sont appliquées. Les résultats de cette dernière phase effectuée avec SpaCy (https://spacy.io/) permettent de réduire le texte aux seuls lemmes des Noms et Adjectifs. Des étapes exploratoires ont permis de déterminer que cet enchaînement de prétraitements fournissait les meilleurs résultats pour la tâche de classification dans notre cas. Le corpus principal est ensuite scindé en sous-corpus pour produire l’ensemble des modèles selon les codes de classement tronqués suivant le niveau.
Enfin, chaque corpus est exploité pour entraîner un classifieur FastText. Là aussi, après plusieurs essais les paramètres ont été fixés suivant le tableau ci-dessous.
| Param | dim | lr | ws | epoch | wordNgrams | loss | cutoff |
| Value | 100 | 0.9 | 5 | 20 | 3 | softmax | 200000 |
Figure 4 : paramètres d’apprentissage fastText
Dans notre cas, la profondeur du plan de classement (arborescence de code) fédéré comprenant Pascal et Francis a été limitée à 3 niveaux, ce qui a produit 69 modèles.
Une fois l’arborescence de codes décorée par les différents modèles, on peut prédire un code domaine pour un nouveau document. Le traitement d’un document à classer commence par l’analyse du contenu textuel puis la prédiction se fait par parcours descendant de l’arborescence de modèles. A chaque niveau, un code domaine (ie. un domaine) est prédit et le modèle correspondant à ce nouveau code est consulté. En fin de parcours, le système propose le code domaine le plus fin. Comme le montre la figure ci-dessus, la consultation du modèle du niveau 1 (001) permet de prédire le code plus fin du niveau 2 [001A à 001E] et ainsi de suite jusqu’au niveau 3 terminal.
Evaluation
Les résultats sont fournis pour les deux plans de classement Pascal et Francis c’est-à-dire au-delà de la 1ère prédiction qui propose un code Pascal ou Francis.
Francis Pascal

La précision, le rappel et la F-mesure sont calculés pour évaluer la pertinence des prédictions de domaines.
Chaque colonne donne les résultats par niveau (ie. profondeur) de prédiction si bien qu’un code domaine de niveau 1 ([001 ou 002.] dans Pascal est prédit avec une F-mesure de 0.96 (predict 0).
On remarque que les indicateurs de qualité baissent en fonction du niveau, ce qui s’explique à la fois par des corpus d’apprentissage toujours plus petits et souvent des jeux d’étiquettes à prédire plus grands au fur et à mesure que l’on descend l’arborescence. Les prédictions de domaine semblent meilleures pour Pascal que pour Francis ce qui peut être lié à la taille des corpus d‘ apprentissage.
Ce système de prédiction de domaines fait désormais partie de la gamme des Web Services développés par l’Inist-CNRS et disponible sur le site ISTEX TDM.
Vous avez un corpus et vous souhaitez en connaître le contenu ?
En lançant pascalFrancisClass sur vos données depuis Lodex, logiciel libre de visualisation, vous obtiendrez pour chaque document l’intitulé de la classe à laquelle il appartient et des représentations graphiques liées.
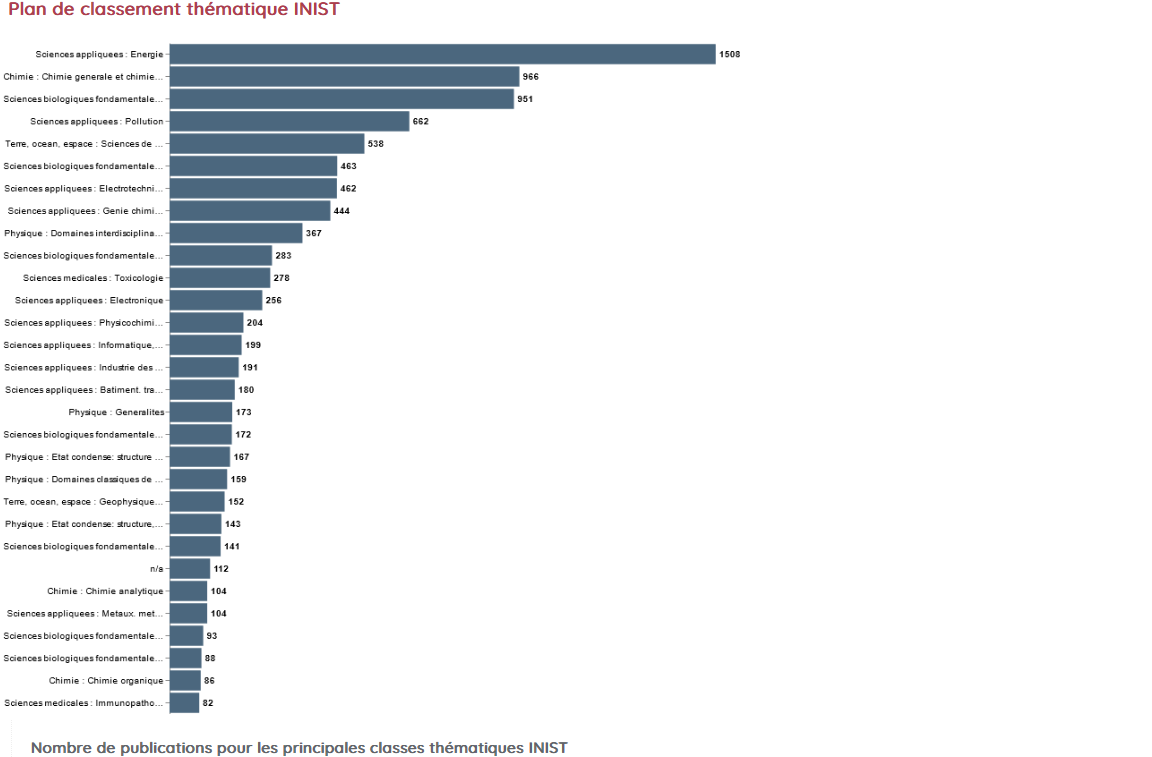
Graphe issu d’une étude réalisée pour l’AtMO Grand-Est (Production scientifique 2007-2020).
Profitez en pour naviguer dans l’ensemble du corpus

Graphe issu du corpus Istex “Coronavirus : SRAS MERS“.
Profitez en pour naviguer dans l’ensemble du corpus
et découvrez d’autres corpus scientifiques