

L’application pilote développée à l’Inist dans le cadre de Visa TM est intitulée “Fouille et exploration de données pour la constitution d’un corpus documenté”. Elle sera déployée sous forme de service en ligne sur OpenMinTeD. Elle permettra l’exploration d’un corpus d’articles scientifiques en texte intégral issu du réservoir ISTEX. Cette exploration inclut, entre autres, une cartographie des domaines scientifiques représentés dans le corpus, obtenue par une méthode de clusterisation (classification automatique non supervisée).
Plusieurs méthodes de clusterisation seront étudiées dans cette étude. Cet article porte sur l’évaluation d’une clusterisation réalisée avec l’outil Neurodoc sur le corpus “géosciences” (voir Sélection du corpus “géosciences” dans ISTEX).
Constitution du corpus
Un travail préalable avait été réalisé pour définir un corpus de documents issus d’ISTEX et relevant du domaine des géosciences. Au sein de cette sélection, le choix a été restreint aux articles de l’éditeur Wiley qui présentent l’avantage d’être tous disponibles dans ISTEX en format XML structuré, ce qui optimise certains des traitements appliqués par la suite en permettant une sélection des champs.
A la date des travaux, 68.757 articles de l’éditeur Wiley étaient présents dans le corpus “géosciences”. L’expérimentation de clusterisation a été réalisée sur un sous-ensemble de 5.000 articles extraits par tirage aléatoire.
Indexation pré-clusterisation
L’outil de clusterisation choisi dans cette phase de l’expérimentation est Neurodoc. Il met en œuvre la méthode des K-means axiales pour réaliser une classification automatique non hiérarchique, puis une analyse en composantes principales pour positionner les clusters et leurs liens sur une carte.
Neurodoc traite des matrices doc-terme, la clusterisation suppose donc une étape préalable d’indexation des documents.
Deux outils ont été expérimentés à cet effet :
- TermSuite
outil d’extraction terminologique développé par le LS2N (laboratoire des Sciences du Numérique de Nantes) et disponible dans OpenMinTeD. Cette application n’étant pas à la base conçue pour réaliser une tâche d’indexation à proprement parler, une opération de réaffectation de chaque descripteur à l’article dont il a été extrait a été appliquée en sortie de TermSuite.
Le traitement est réalisé après extraction d’ISTEX, sur les zones titre, résumé et texte de l’article (en excluant les références bibliographiques). Une sélection des descripteurs extraits a ensuite été faite sur la base de leur catégorie grammaticale, de leur fréquence et de leur pertinence (sélection par un expert). - Teeft (Term Extraction for English FullText)
outil d’indexation développé par l’équipe ISTEX de l’Inist. L’indexation est réalisée avant chargement dans ISTEX, sur la totalité du contenu textuel des articles. La clusterisation a pris en compte la totalité des descripteurs.
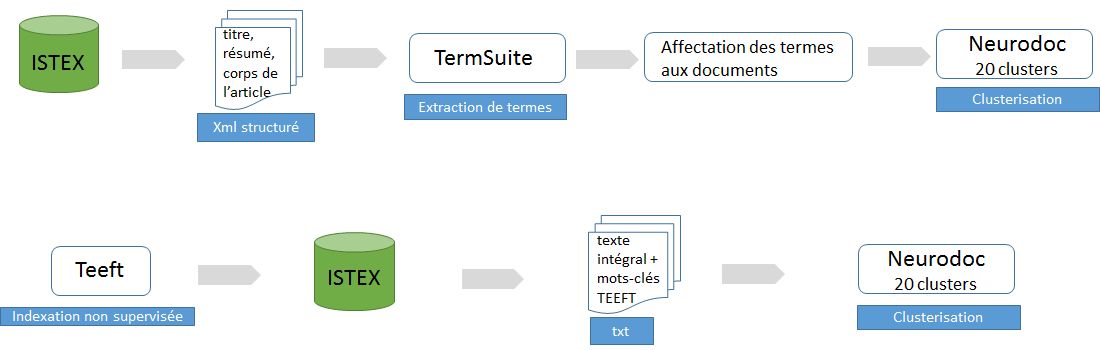
Enchaînement des étapes pour chacune des chaines de traitement
Clusterisation
Neurodoc a été lancé sur le corpus indexé par chacune des deux méthodes, en fixant à 20 le nombre de clusters souhaité en sortie.
L’outil fournit des cartes illustrant les clusters et leurs liens ainsi que des tables permettant de connaître les descripteurs associés à un cluster et leur poids.
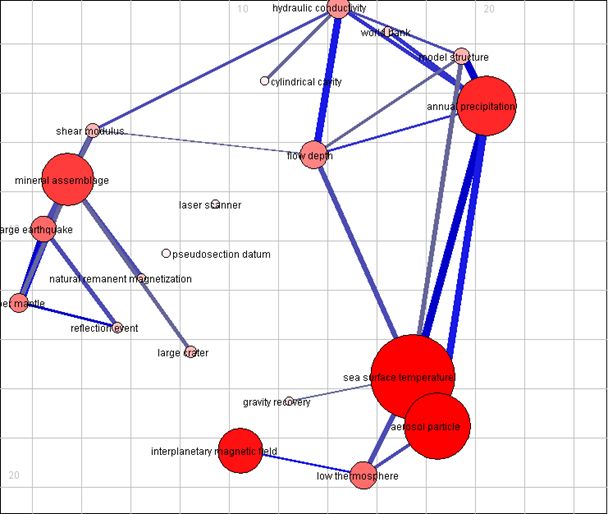
Exemple de carte de clusters obtenue avec Neurodoc sur le corpus Géosciences
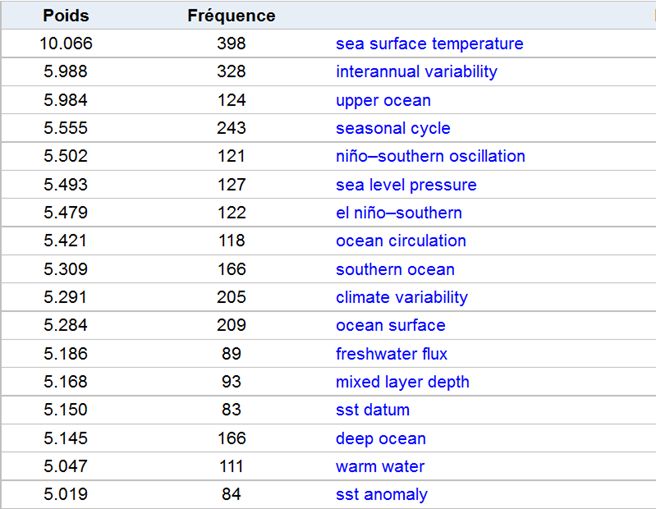
Exemple de contenu d’un cluster généré par Neurodoc
Évaluation de la clusterisation
L’évaluation a été réalisée par un expert du domaine des géosciences. Il a étudié la cohérence scientifique de chaque cluster et leur a attribué une thématique en se fondant sur l’analyse de :
- la liste des descripteurs générés par TermSuite ou Teeft pour indexer les articles de chaque cluster, classés selon un poids décroissant
- la liste des titres des articles regroupés dans chaque cluster
- la liste des périodiques représentés dans chaque cluster, ainsi que leur fréquence
L’expert résume ses conclusions comme suit :
- globalement, une majorité des thématiques des clusters sont communes aux deux classifications, même si les descripteurs qui les décrivent sont parfois libellés de façon différente (effet de la méthode d’indexation).
L’analyse de l’expert montre ainsi que 75% des thématiques issues de l’indexation TermSuite sont également mises en avant avec Teeft, et que 85% issues de l’indexation Teeft sont également mises en avant avec TermSuite.
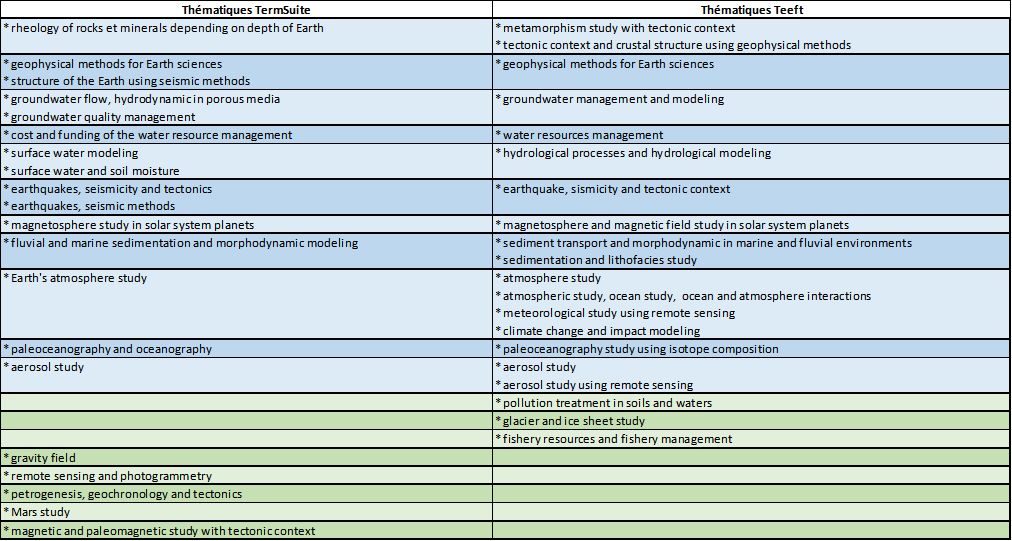
Correspondance établie par l’expert entre les thématiques issues de la clusterisation sur les deux indexations du corpus
- présence dans le corpus d’articles traitant de domaines “périphériques” aux géosciences, bien qu’aucun périodique spécifique à ces thématiques n’ait été retenu dans la phase de sélection du corpus.
Ceci est attribué au poids important dans le corpus de la revue “Journal of Geophysical Research”, qui traite bien des géosciences mais peut comporter des articles très généralistes ou abordant des thématiques périphériques. - certaines thématiques importantes en géosciences, comme la minéralogie ou la paléontologie, sont bien représentées dans le corpus mais n’apparaissent pas sous la forme de clusters spécifiques.
Ceci est attribué au fait que peu de périodiques Wiley traitent exclusivement de ces thématiques. Elles seraient peut-être apparues avec une clusterisation comportant plus de 20 clusters. - les deux outils d’indexation semblent complémentaires : certains clusters sont mis en avant avec l’indexation Teeft et n’apparaissent pas avec l’indexation TermSuite, certains clusters sont mis en avant avec l’indexation TermSuite et n’apparaissent pas avec l’indexation Teeft.
- dans les deux cas les clusters sont cohérents et homogènes
- les deux méthodes d’indexation employées sont jugées valides pour caractériser le corpus géosciences
- la clusterisation avec Neurodoc produit une image cohérente du corpus “géosciences”